X. Intelligence


Introduction
Ce chapitre distingue les intelligences individuelle, collective et artificielle, car (i) l'intelligence collective est (plus que) la somme d'intelligences individuelles, et (ii) l'intelligence artificielle, telle qu'elle a été développée jusqu'à aujourd'hui, est une technologie d'intelligence collective dans la mesure où elle repose sur l'exploitation de données produites par la collectivité humaine.
Il est également utile de distinguer les notions de :
- science, qui vise à comprendre les phénomènes naturels ;
- techniques, qui visent à exploiter des connaissances acquises par la science, afin d'améliorer notre bien-être (notion d'utilité et d'efficacité), et cela de deux façons possibles :
les techniques naturelles le font sans transformer l'environnement, et par conséquent minimisent l'énergie "consommée" (en fait transformée), ce qui minimise la production anthropique de chaleur (cf. les premier et second principes de la thermodynamique : allocation-universelle.net/thermodynamique#energie-principes);
les techniques artificielles, encore appelées technologies, le font au moyen de machines (avions, ordinateurs, bases de données, ...), fabriquées par le conditionnement (travail) de matières premières (capital), ce qui requiert de transformer beaucoup d'énergie, et donc de produire beaucoup de chaleur.
La relation de causalité n'est pas toujours dans le sens théorie (fondamentale) ⇒ technologies. Ainsi c'est la création, par essais-erreurs, de la machine à vapeur (18° siècle) qui a induit le développement d'un corpus théorique dénommé "thermodynamique" (19° siècle).
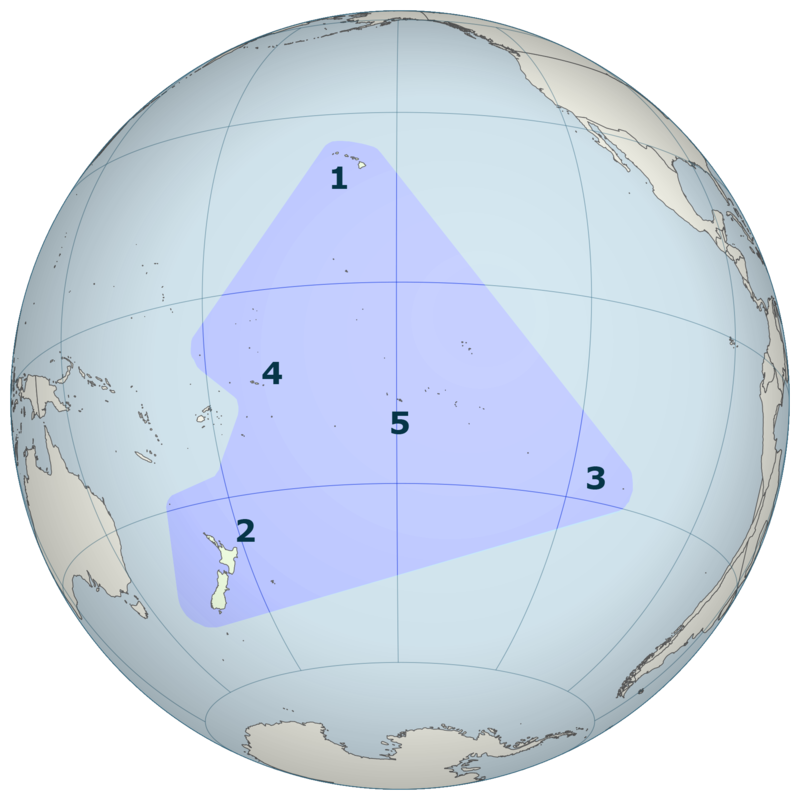
Les îles situées à l'intérieur du « triangle polynésien » forment la Polynésie (1 : Hawaï ; 2 : Nouvelle-Zélande ; 3 : Île de Pâques ; 4 : Samoa ; 5 : Tahiti) [source].
Par exemple, la géolocalisation est une technique qui peut être appliquée :
naturellement, à l'instar des populations indigènes de Polynésie pour se déplacer entre îles, en observant les positions des étoiles, la direction du vent et des courants, ...) ;
- artificiellement : cf. GPS, qui fonctionne au moyen de satellites.
La dynamique du progrès est très différente entre :
d'une part, les techniques naturelles utilisées par l'ensemble des organismes vivants, dont le progrès résulte du phénomène lent qu'est l'évolution, qui produit des techniques extrêmement efficaces en terme de consommation énergétique ;
d'autre part, les techniques artificielles des humains, qui progressent beaucoup plus vite, mais au prix d'une énorme consommation d'énergie, et donc de production de chaleur.
L'intelligence est ce qui permet la science et les techniques, celles-ci étant l'expression de celle-là.
Il y une relation de boucle rétroactive entre les trois couples constitutifs du triangle individuel-collectif-artificiel :
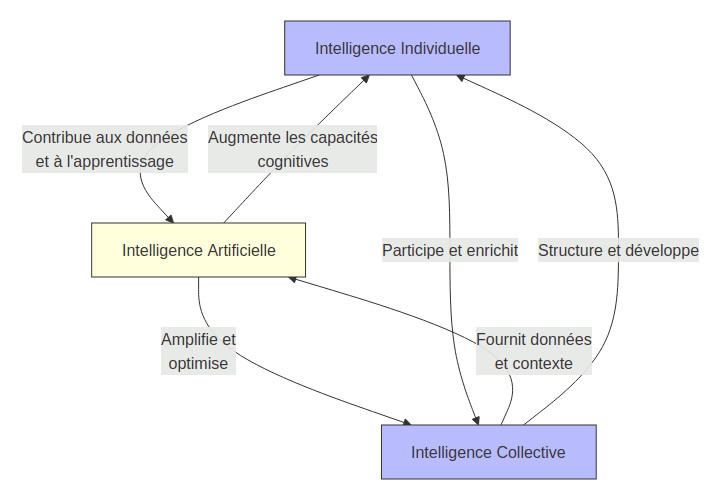
Le triangle des intelligences - © François Jortay
Chaque boucle crée des effets d'amplification et de transformation mutuels. La dynamique globale fait émerger un système d'intelligence augmentée où les trois dimensions se renforcent mutuellement.
Il importe cependant que l'IA soit également accessible aux individus, ce qui requiert un contrôle démocratique de moyens de production de l'IA, via des coopératives publiques.
Intelligence individuelle
2. Composantes
3. Conscience
4. Capacités analytiques
5. Apprentissage
6. Fondements biologiques
7. Humain vs animal
8. Humain vs machine
9. Déclin
Humaine
Partant de l'hypothèse que l'intelligence existe en tant que caractéristique propre aux organismes vivants, nous entendons par "intelligence individuelle", l'intelligence d'un organisme biologique. Nous nous intéressons ici en particulier à l'intelligence individuelle des humains.
Composantes
L’épistémologue Jean Piaget, fondateur du structuralisme génétique et spécialiste de l’apprentissage, disait que « l’intelligence, ça n’est pas ce que l’on sait, mais ce que l’on fait quand on ne sait pas ».
1. Composantes quantitatives2. Composantes qualitatives
Composantes quantitatives
On peut distinguer deux types de composantes quantitatives de l'intelligence, consistant en la capacité de traitements des informations, et pouvant être mesurées objectivement par :
- la capacité de stockage (mémorisation) des informations ;
- la vitesse de "calcul" des informations.
Ces capacités de traitement de données ne sont pas typiquement humaines puisqu'elles sont également (i) reproductibles par des machines (qui peuvent dépasser les capacités humaines en la matière), et (ii) observées chez les animaux (avec des performances généralement inférieures à celles des humains).
Dans tout système "intelligent" (biologique ou électronique), ces deux capacités sont précédées par la perception & collecte de données brutes, puis se concluent par la phase de représentation des données traitées, et de leur interprétation.
- perception (collecte de données), au moyen d'un système sensoriel ;
- mémorisation ;
- traitement ;
- représentation ⇒ interprétation.
Il y donc, entre l'étape initiale de perception des données brutes et l'étape finale d'interprétation de leur représentation, une série de phases intermédiaires, qui peuvent biaiser les données, quantitativement (ex. : pertes de mémoire) et qualitativement (ex. erreurs de calcul).
Questionnement : qu'est-ce qui distingue la représentation de l'interprétation ? Pour répondre à cette question il faudra commencer par déterminer comment l'une et l'autre fonctionnent.
Les différences individuelles apparaissent notamment au niveau de l'accumulation des informations avec le temps. Ainsi pour Landemore, le concept de sagesse est plus riche que celui d’intelligence, puisqu’il recouvre les notions d’expérience, de connaissance éprouvée par le temps et, de façon plus générale, celle d’intelligence diachronique [source]. Cependant avec la vieillesse, la vitesse de traitement des données tend à baisser.
L'analyse quantitative doit être complétée par un volet qualitatif, si l'on veut cerner l'intelligence dans toute la subtilité et diversité que l'on constate chez les humains ...
Composantes qualitatives
Dans la section précédente nous avons souligné le fait que les composantes quantitatives de l'intelligence se retrouve aussi bien chez les humains que dans l'IA. Il y a cependant une différence de nature dans leur fonctionnement : alors que les capacités quantitatives des ordinateurs sont mesurées en termes binaires, celle des humains sont plutôt d'ordre analogique.
L'unité logique des logiciels d'un ordinateur est le byte (noté B ou o), soit huit bits (noté b). Un bit est une unité qui peut prendre deux valeurs : 1 (présence de courant électrique) ou 0 (absence de courant électrique). Ainsi dans un ordinateur, les capacités de stockage sont mesurées en bytes, et la vitesse de calcul en bytes/seconde.
Il y a donc une différence de nature entre systèmes biologique et électronique. Alors que dans ce dernier les données sont échangées uniquement via des signaux électriques, chez les organismes biologiques, les signaux électriques peuvent être combinés à des signaux chimiques (cf. clipedia-txt.net/biologie#systeme-nerveux-cerveau), ce qui augmente considérablement les potentialités des systèmes biologiques, en termes de fonctionnalités et de performance, ... par unité d'énergie consommée.
Dans la section consacrée consacrée à l'IA, nous verrons que l'efficacité énergétique des humains est très supérieure à celle des ordinateurs, ce qui conduit les ingénieurs à concevoir des ordinateurs biologiques, composés de cellules biologiques ...
Parmi les composantes qualitatives de l'intelligence, on peut distinguer :
l'intelligence critique, relevant de la capacité à évaluer la qualité d'une information (est-elle vraie ou fausse ? ; est-elle baisée ? ; la différence entre la réalité et sa représentation est-elle fortuite ou intentionnelle ? ; ... ;
- l'intelligence émotionnelle, relevant du jugement de valeur ;
- l'intelligence relationnelle, relevant de l'empathie (et pouvant être guidée par la bienveillance comme par la malveillance).
- l'intelligence créative, relevant de l'imagination.
Les machines sont capables d'imiter ces capacités, ce qui est déjà pas mal, et d'autant plus lorsqu'il y a amplification de la capacité. Par "imiter", nous entendons ici l'absence de conscience, d'intentionnalité ou encore d'éthique. Nous postulerons ainsi que, contrairement à la réaction, la proaction est le résultat d'une volonté, laquelle requiert une conscience : proaction ⇐ volonté ⇐ conscience.
Conscience
Définition
« La conscience est un concept complexe et multifacette qui fait référence à la capacité d'un être vivant, en particulier l'être humain, à percevoir, à ressentir, à avoir une compréhension de soi-même et du monde qui l'entoure. C'est l'état mental de veille et d'auto-observation qui nous permet de penser, de ressentir, de réfléchir, de prendre des décisions et d'interagir avec notre environnement. La conscience englobe la perception sensorielle, la réflexion, l'émotion, la mémoire, la pensée, et d'autres processus cognitifs » [chatGPT, nov. 2023].
Ces propositions composites suscitent la question de la relation entre intelligence (I) et conscience (C) :
- I ⇒ C ?
- I ⇐ C ?
- I ⇔ C ?
- I ≡ C ?
- ... ?
Le philosophie et physicien Dominique Lambert, en énonçant des capacités supposées distinguer l'humain des autres animaux (et des robots), suggère une forte intrication entre conscience et intelligence. Ainsi selon lui, l'humain serait particulièrement efficace dans sa capacité à :
- dépasser sans cesse les limites du langage pour l'interpréter et donner du sens ;
- sortir de ses propres représentations décrivant sa nature ;
- assumer des risques en dehors de ce qui est rigoureusement calculable ;
Lambert cite cet élément dans le cadre d'une argumentation contre l'abandon de nos décisions à des systèmes d'intelligence artificielle (notamment dans la justice) qui, par nature, ne seraient pas capables de reproduire cette capacité.
- limiter sa toute-puissance et sa toute-maîtrise pour faire place à l'autre [source].
Dans son roman "Pantagruel" écrit en 1532, François Rabelais fait dire à Gargantua écrivant à son fils Pantagruel : « science sans conscience n’est que ruine de l’âme », distinguant ainsi le savoir de l'utilisation qu'on en fait.
Sur base des définition énoncées dans la section #composantes-qualitatives, on pourrait proposer que : « l'intelligence sans émotion ni empathie et bienveillance, n'est que ruine de l'âme », et ainsi souligner le rôle et l'importance de la composante qualitative de l'intelligence.
L'avertissement que nous adresse Rabelais suggère implicitement la notion de responsabilité, ce qui conduit à d'autre notions, telles que le libre arbitre et la volonté.
Déterminisme
inconscient ?
Une expérience réalisée en 1983 par Benjamin Libet montre que l’activation cérébrale (supposée inconsciente) précède la décision consciente. Dans une autre expérience réalisée en 2008 par Chun Siong Soon l'activation cérébrale est observée jusqu'à 10 secondes avant la décision consciente, et en outre l'observation des zones cérébrales activées permet dans 60% des cas de prédire correctement le type de décision que l'individu observé prendra. En 2011, utilisant une autre technologie Itzhak Fried obtient un taux de prédiction correcte de 80%, 700 millisecondes avant la décision consciente [source]. Doit-on en déduire que le libre-arbitre ne serait qu'une illusion rétrospective sur nos actes ? Ne serions-nous que des feuilles balancées par le vent du déterminisme ?
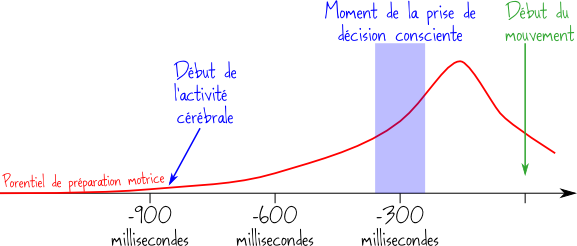
Quelques questionnement et faits viennent tempérer une éventuelle réponse affirmative à ces questions :
L'activation neuronale précédant la décision n'est-elle pas déterminée par la participation volontaire de l'individu à l'expérience ?
Si nous subissons, en provenance de notre environnement, des influences dont nous n'avons pas nécessairement conscience, il demeure que c'est justement le laps de temps entre intention/volonté et décision qui permet éventuellement à l'individu de ne pas passer à l'acte. Ainsi la conscience est liée à la réflexion, laquelle procède selon un mécanisme de boucle de rétroaction et d'inférence bayésienne [source].
Le phénomène étudié dans les expériences mentionnées ci-dessus ne doit pas être confondu avec le réflexe, qui est une réaction musculaire stéréotypée et très rapide à un stimulus, sans intervention du cerveau et de la volonté consciente
Des expériences ont montré que les individus qui croient dans le déterminisme de l'être humain, ont plus tendance à se comporter de façon malhonnête que des individus croyant dans leur libre arbitre. Ainsi, fondée ou non, la croyance dans le libre-arbitre présente l'avantage d'être socialement éthique.
Biais
cognitifs
Les individus n'étant généralement pas conscient de leurs biais cognitifs, l'interaction avec des systèmes intelligents peut aider à faire émerger ces biais dans la conscience. C'est incontestablement une prouesse de l'intelligence humaine que de concevoir de tels outils.
Perception et conscience (2020, 2m22s)
Axel Cleeremans est professeur de psychologie cognitive à l'Université Libre de Bruxelles.
Conscience
artificielle ?
Pourrait-on fabriquer des machines conscientes ? Oui affirme la théorie computationnaliste, à l'instar du psychologue Philip Johnson-Laird qui énonce les conditions suffisantes à vérifier pour créer des ordinateurs conscients [source : « A computational analysis of consciousness » 1988]. Au contraire, le mathématicien Roger Penrose soutient que les ordinateurs, considérés comme des machines de Turing ou des systèmes formels, sont fondamentalement dans l'incapacité de modéliser l'intelligence et la conscience. Les ordinateurs étant des systèmes déterministes, ils sont soumis aux limitations des systèmes formels, par exemple l'insolvabilité du problème de l'arrêt ou le théorème d'incomplétude de Gödel. Selon Penrose, l'esprit d'un authentique mathématicien est capable de surmonter ces limitations, car il a la capacité de s'extraire au besoin du système formel dans lequel il raisonne, quel que soit celui-ci [source].
Capacité analytique
Notre capacité de raisonnement est fondée sur une capacité à synthétiser une problématique c-à-d à identifier les facteurs explicatifs d'un phénomène, puis à décrire leur relations, sous forme d'un modèle.
Une méthode de modélisation est la théorie des graphes, dont des applications peuvent prendre la forme d'algorithmes.
La capacité d'abstraction, dont le langage mathématique est une expression, constitue une déterminant majeur de la capacité analytique des humains, laquelle est constamment augmentée par l'extension du langage mathématique aux processus informatiques, permettant ainsi le traitement de données en quantités et vitesses phénoménales.
Python est un langage très populaire pour coder des algorithmes.
Ces capacités d'abstraction de l'intelligence humaine ne se retrouvent pas (ou à des ordres de grandeur très inférieurs) chez les animaux. Par contre, les ordinateurs surpassent généralement les capacités d'abstraction des humains. Ainsi par exemple, notre capacité à interpréter la notion mathématique d'espace s'effondre à partir de la dimension 3 (qui est celle de notre environnement physique), alors que la limite des ordinateurs se situe à un ordre de grandeur très supérieur (et rapidement croissant, grâce au progrès technologique).
L'analogie est une autre capacité fondamentale de l'intelligence.
Un exemple d'analogie est « abc est à abd ce que pqr est à ... ? », dont une notation mathématique est abc:abd :: pqr:?
Méthode
scientifique
Une problématique fondamentale de la dynamique cognitive est que le scientifique ne peut totalement s'extraire des phénomènes qu'il étudie, ce qui peut biaiser ses analyses, notamment en influençant les données brutes, ou encore via l'interprétation qu'il fait des phénomènes observés. La méthode scientifique vise à minimiser ces biais, et plus généralement à rationaliser l'étude des phénomènes naturels. Elle s'inscrit dans un cycle rétroactif composé de quatre phases : observation --> théorisation --> prédiction --> expérimentation --> observation.
La liste qui suit, non exhaustive, énonce des notions qui composent la méthode scientifique :
- hypothèse & thèse ;
- observation ;
- mesure ;
- typologie & classification ;
- théorie ;
- modélisation ;
- démonstration ;
- expérimentation ;
- protocole ;
- calcul ;
- probabilité ;
- logique ;
- référentiel & relativité ;
- induction & déduction ;
- réfutation & réfutabilité ;
- heuristique ;
- évaluation par les pairs ;
- transdisciplinarité & inter-disciplinarité ;
- ...
Il n'y a évidemment aucune raison pour que la rationalité ne soit appliquée que dans le domaine scientifique. Il est dans l'intérêt de tout individu d'appliquer les principes ci-dessus, notamment dans la gestion de projets, ou encore dans ses relations avec autrui. C'est pourquoi la méthode scientifique devrait faire partie de la formation de base universelle.
Déduction vs induction
La déduction consiste à tirer des conclusions logiques à partir de prémisses données, tandis que l'induction consiste à généraliser à partir d'observations spécifiques pour tirer des conclusions plus larges.
Il y a une différence qualitative : le résultat d’une inférence suivant un raisonnement inductif, même basé sur des milliards d’exemples, peut toujours être démenti par un contre-exemple ou par plusieurs contre-exemples, tandis qu'une conclusion obtenue par déduction, si les prémisses sont vraies et le raisonnement valide, est nécessairement vraie. Ainsi on peut dire que la déduction est une démarche théorique tandis que l'induction est une démarche expérimentale. Les deux approches sont complémentaires : l'induction permet de formuler des hypothèses à partir d'observations, tandis que la déduction permet ensuite de tester ces hypothèses en dérivant leurs conséquences logiques et en les confrontant à la réalité.
Il existe également un troisième type de raisonnement, l'abduction, qui consiste à formuler la meilleure explication possible à partir d'observations (utilisé en sciences ou en diagnostics
En matière de déduction, les humains ont historiquement montré une grande habileté, en particulier dans des domaines tels que la logique formelle, les mathématiques et la résolution de problèmes. Les compétences en déduction des humains peuvent être très développées et peuvent rivaliser efficacement avec celles des systèmes d'IA, en particulier dans les domaines où la compréhension conceptuelle et la manipulation symbolique sont importantes.
En revanche, en matière d'induction, les systèmes d'IA ont souvent un avantage significatif en raison de leur capacité à traiter de grandes quantités de données et à identifier des modèles complexes. Les algorithmes d'apprentissage machine et d'apprentissage profond sont capables d'apprendre à partir de vastes ensembles de données pour faire des prédictions et prendre des décisions dans des domaines tels que la reconnaissance de motifs, la classification, la prédiction et bien d'autres.
Apprentissage et adaptation
Adaptabilité : capacité d’améliorer les performances grâce à l’apprentissage par l’expérience [source].
On pourrait réécrire cette définition comme suit :
expérience ⇒ apprentissage ⇒ amélioration des performances ≡ adaptation.
- expérience ≡ collecte de données
- apprentissage ≡ analyse et transformation des données en informations.
L'apprentissage, qui repose notamment sur la collecte et l'intégration d'informations, permet l'adaptation d'une entité (individu ou organisation) à son environnement (ou plus exactement aux changements dans la relation biunivoque avec l'environnement).
Selon le physicien François Roddier, « Pris isolément, tout animal cherche à maximiser ses chances de survie (de dissiper de l’énergie). Pour cela, il répond à des stimuli (informations venant de l’environnement) en déclenchant des actions appropriées (travail mécanique). Le comportement le plus intelligent est celui qui déclenche le plus rapidement les actions les mieux appropriées » [source].
L'intelligence apparaît ainsi comme une capacité à comprendre notre environnement et à y déterminer l’action à réaliser pour optimiser des "conditions de vie" – le "bien-être" pour les économistes – tout en minimisant la consommation d'énergie.
La notion de compréhension est ici fondamentale. Elle induit la relation conscience ⇒ volonté ⇒ proaction, qui ne se réduit pas à la simple la capacité d'adaptation, également observée chez les corps inertes (matière non vivante). Ainsi les solides se dilatent à la chaleur, les liquides prennent la forme de leur conteneur, etc. Il n'y a pas là d'intentionnalité, mais simple réaction plutôt que proaction.
À supposer évidemment que l'intentionnalité ne soit pas une illusion ...
En toile de fond de cette dynamique conduisant du savoir à l'action, il y a l'apprentissage.
Bak et Stassinopoulos ont conçu un modèle de l'apprentissage, qui a été expérimenté en proposant un jeu à un singe : lorsque le voyant est vert il doit appuyer sur la pédale de droite, et quand il est rouge sur la pédale de gauche. À chaque réussite il reçoit une récompense (une cacahuète). Au début, la distribution des résultats est aléatoire, mais progressivement elle se rapproche de 100% d'essais réussis : l'apprentissage est alors réalisé. Le graphique suivant permet d'expliquer le mécanisme de cet apprentissage. Chaque essai correspond à un chemin entre la perception de la couleur et l'action qu'elle provoque (ou pas). Les connexions neuronales des chemins correspondant à des essais réussis serait progressivement renforcées (on dit que leur seuil est abaissé) tandis que les chemins correspondant à des essais ratés seraient progressivement inhibée (seuil renforcé) [source].
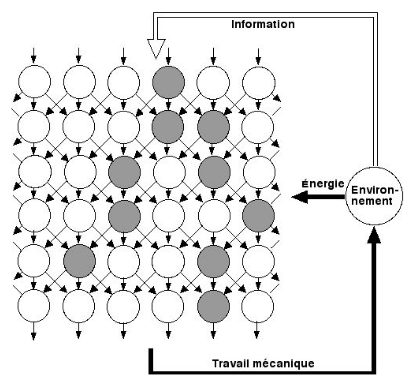
François Rodier propose une intéressante analyse thermodynamique de ce modèle. Elle repose sur le principe du cycle convectif.
Cycle convectif
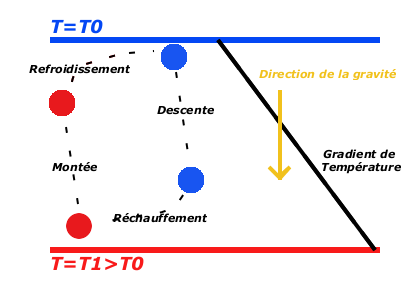
Que se passe-t-il dans la casserole ?
Le modèle de cerveau de Bak et Stassinopoulos ci-dessus reçoit de l’information (Q2) de l’environnement sur lequel il agit (W=Q1-Q2) de façon à obtenir de l’énergie (Q1). Ainsi, à l'instar d'une machine thermique, ce modèle repose sur deux entrées et une sortie : l'une des entrées correspond aux calories apportées sous forme de nourriture (et correspond à l'apport de calories de la source chaude d'une machine thermique, c-à-d à une entrée d'entropie), tandis que l'autre entrée correspond à un apport d'information (et correspond à la source froide de la machine thermique, c-à-d à une sortie d'entropie).
Lorsqu'un neurone reçoit des signaux d'autres cellules il se charge électroniquement. Lorsque la charge dépasse un certain seuil le neurone est excité et transmet l'information à d'autres neurones. On observe alors des avalanches d'excitations. Les neurones excités (cercles gris) forment des domaines d'Ising d'autant plus étendus que les seuils sont faibles. (c-à-d que "les barrières sont basses"). La probabilité pour qu'un de ces domaines connecte les neurones sensoriels (ligne d'entrée dans le haut du graphique) aux neurones moteurs (ligne de sortie dans le bas du graphique) s'obtient en résolvant un problème mathématique dit de percolation [source p. 89-90].
François Roddier souligne que le modèle de Stassinopoulos et Bak relève de l'auto-organisation, et que celle-ci procède à l’aide d’oscillations de part et d'autre d’un point critique, seuil de percolation. Deux paramètres sont impliqués :
- l’intensité des connections entre les neurones (l'amplitude des avalanches d'excitations) : par analogie avec les cycles de Carnot, elle joue le rôle d’une pression : elle mesure un flux de charge comme la pression mesure un flux de particules qui frappent une paroi ;
- le seuil à partir duquel l’information est transmise d’un neurone à l’autre : par analogie avec les cycles de Carnot, les seuils jouent le rôle d’une température : des seuils bas facilitent leur franchissement (comme le ferait une température élevée) tandis que des seuils élevés empêchent leur franchissement (comme le ferait une température basse).
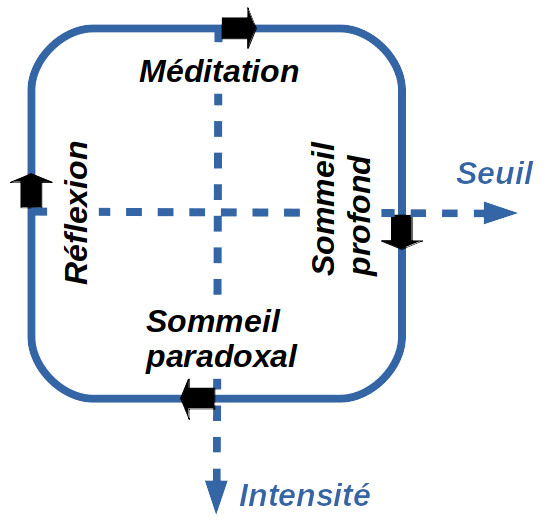
Le graphique ci-contre expose la dynamique entre seuils et intensités, au regard du cycle diurne du cerveau.
Ces deux paramètres oscillent au voisinage d'un point critique de sorte que l'apport énergétique est maximisé (cf. les cacahuètes qui récompensent les essais réussis du singe). Ces oscillations sont très utiles car, si trop de neurones moteurs sont excités, la valeur des seuils sera augmentée, et inversement (ainsi pour réfléchir, le cerveau doit être dans un état entre le sommeil et l'hyperactivité) Les fluctuations aléatoires permettent que le système ne reste pas piégé dans un optimum secondaire (cf. les oscillations de la température dans l'algorithme de recuit simulé, ou encore les équilibres ponctués en biologie) [source p. 89-90].
Roddier souligne que le modèle de Bak et Stassinopoulos permet d'expliquer :
- pourquoi le cerveau demeure capable de réapprendre même après ablation partielle : le système peut continuer de fonctionner même après suppression d'une partie des colonnes du graphique supra ;
- pourquoi très souvent au moment du réveil une solution apparaît au problème qui nous accaparait la veille : c'est à ce moment là que le cerveau traverse l'état critique [source p. 89-90].
Cycle diurne du cerveau
Le physicien François Roddier note l'analogie entre l'activité cyclique du cerveau telle que mesurée par électro-encéphalogramme (ondes thêta, bêta, alpha et delta), et le cycle convectif, ou encore le cycle des saisons [source].
| Cerveau | Convectif | Saison |
|---|---|---|
| Sommeil paradoxal (θ : 4-8Hz) | Réchauffement | Hiver (germination) |
| Réflexion (β : 15-30Hz) | Ascension (extension) | Printemps (croissance) |
| Méditation (α : 9-14Hz) | Refroidissement | Été (apogée) |
| Sommeil profond (δ : 1-3Hz) | Descente (compression) | Automne (régression) |
Conclusion importante : ces faits suggèrent que l'apprentissage n'est pas lié à la conscience. Nous verrons d'ailleurs que l'IA peut "apprendre".
Fondements biologiques
Selon l'état actuel des connaissances, le cerveau serait le siège de l'intelligence. Les neurones, connectés en un vaste réseau par des axones, communiquent entre eux au moyen d'une combinaison de messages chimiques (les neurotransmetteurs) et de signaux électriques (les potentiels d'action).
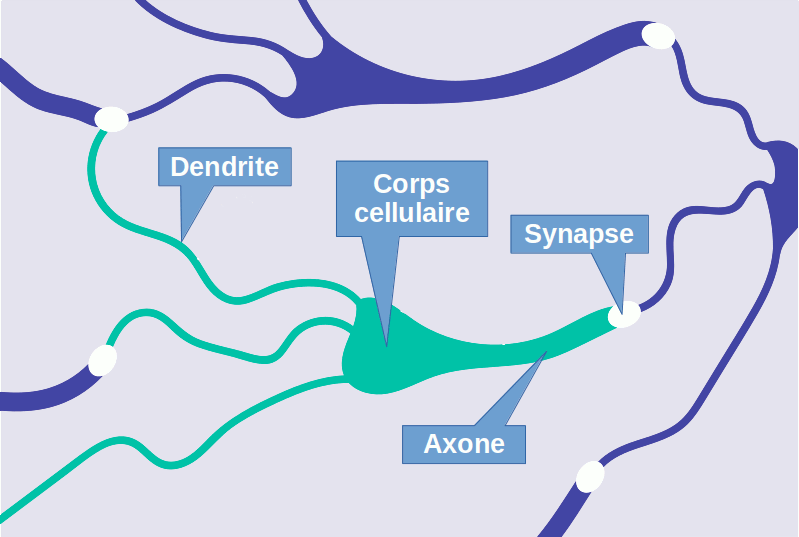
Voir aussi : https://clipedia-txt.net/biologie#systeme-nerveux-cerveau
La plasticité cérébrale, c-à-d la capacité du cerveau à s'adapter et à changer en réponse à l'expérience et à l'apprentissage repose notamment sur la capacité des synapses (les connexions entre les neurones) à être modifiées en fonction de l'activité neuronale. Ainsi l'apprentissage et la mémorisation sont associés à des changements dans la force des synapses : lorsqu'une synapse est régulièrement utilisée, elle peut renforcer sa connexion (potentiation synaptique), tandis que l'inactivité peut entraîner une affaiblissement de la connexion (dépression synaptique).
Les recherches sur les fondements biologiques de l'intelligence reposent notamment sur la distinction entre savoir routinier (inconscient) vs non routinier (conscient), ou encore entre savoir inné et acquis.
Concernant la mémoire, depuis le début des années 1970 et les études menées chez l’humain après des traumatismes cérébraux, on fait la distinction entre deux types de mémoire. La mémoire sémantique, qui est la mémoire factuelle de toutes les connaissances que nous avons sur le monde qui nous entoure, et la mémoire dite “épisodique”, qui est la mémoire des événements personnellement vécus et ancrés dans un contexte spatio-temporel. C’est cette mémoire épisodique qui est par exemple défaillante chez les personnes atteintes de la maladie d’Alzheimer [source].
Humain vs animal
Tout propriétaire d'un animal domestique peut constater que les animaux partagent avec l'homme la souffrance et le plaisir psychique. L'animal est donc un être sensible. Mais ce n'est pas tout. Des expériences suggèrent que les animaux sont capables d'inventer, de se projeter dans l'avenir, de comportements altruistes, d'éprouver un sens de la justice [source], ou encore de pratiquer l'humour (sous forme de jeux, tels que surprendre par derrière, voire simuler la colère) [source].
Se basant sur l'observation de différences de mode de vie entre entre groupes d'une même espèce, certains scientifiques parlent de "cultures animales". D'autres auraient même constaté des modifications comportementales dans le temps, ce qui les conduit à parler d'"accumulation culturelle", c-à-d d'évolutions sociétales dans le monde animal ... [source] .
Antropomorphisme
et wokisme ?
Dans quelle mesure ces travaux scientifiques sont-il biaisés par des biais d'expérimentation et d'interprétations anthropomorphiques, biais cognitifs très fréquents dans la pensée antispéciste et wokiste [source1, source2] ?
Métaphysique. Ainsi le sentiment religieux, ou encore la volonté de comprendre les lois de la nature pour le seul plaisir de la connaissance semblent spécifiques au genre humain, et le distinguer de l'animal (et de la machine).
Le suicide est-il spécifique au genre humain, ou la propension au suicide augmente-t-elle avec le degré d'intelligence de l'espèce considérée ? [source].
Langage et pensée. Quand on compare les langages humains aux systèmes de communication des primates non humains, on constate qu'il n'y a pratiquement pas d'aspect combinatoire chez ces derniers (cf. notion de grammaire). Ils ont bien un lexique, composé uniquement de mots, et peuvent composer des énoncés, mais ne dépassant quasiment jamais l'addition de deux mots. Il n'y a donc rien d'équivalent à la récursivité du langage humain, qui permet de créer une infinité potentielle de messages [source].
Commerce. La pratique des échanges commerciaux est préférable aux invasions et à l’esclavage, raison pour laquelle Montesquieu l'avait identifiée comme une antidote à la guerre. Or on observe des colonies de fourmis se faire la guerre, mais aussi échanger des biens (larves, nourritures, travailleurs). Cependant on a pas découvert chez des animaux l'usage d'une forme où l'autre de monnaie, comme substitut au troc. Ce fait montre que, même à supposer qu'il n'y ait pas de différence de nature entre hommes et animaux), il y a au moins une différence d'échelle dans les capacités qui constituent cette nature.
Civilisation. À une étudiante qui lui demandait ce qu’elle considérait comme le premier signe de civilisation l’anthropologue Margaret Mead ne mentionna pas les traditionnels silex ou l'usage du feu mais ... un fémur cassé qui avait guéri. Mead expliqua que dans le règne animal, un individu dont la patte est cassée sera éliminé par des prédateurs (éventuellement de sa propre espèce) en l'espace de quelques jours voire quelques heures, s'il ne peut les fuir. Un fémur cassé qui a guéri est la preuve que quelqu’un a pris soin du blessé jusqu’à son rétablissement. « Aider quelqu’un d’autre à traverser la difficulté c’est le début de la civilisation » conclut l’anthropologue [source].
Appétit intellectuel. Les animaux ne font pas de recherche fondamentale (dont la caractéristique, qui la distingue de la R&D, est de ne pas être motivée par d'autre objectifs déterminés que celui de découvrir). On pourrait être tenté d'y rapprocher le jeu, dont les animaux en bas âge sont coutumiers, et qui constitue certes une méthode de d'apprentissage efficace. Cependant, il n'y a là aucune volonté d'apprendre, mais seulement de jouer et d'imiter. La conséquence (l'effet) est identique, mais la méthode diffère.
Innovations et progrès. Ainsi, contrairement aux animaux, les humains continuent de progresser après avoir atteint l'âge adulte. En outre, les progrès individuels se propagent au niveau sociétal, grâce à son accumulation sous forme de mémoires matérielles (livres, ordinateurs, ...), au-delà de la durée de vie des individus (progrès civilisationnel).
Les humains progressent par un processus d'innovation double :
- imaginer d'autres causes d'un effet déterminé, pour améliorer la productivité de cet effet ;
- imaginer d'autres effets d'une cause déterminée, pour enrichir les utilisations de cette cause.
La crainte d'éventuelles calamités futures, et la conception anticipative de stratégies pour minimiser leurs conséquences, ne s'observe pas chez les animaux. Là encore, il ne faut pas confondre l’anticipation de schémas de causalité déjà observés (dont sont capables les animaux), et l’inférence de nouvelles possibilités à partir d’expériences passées (non observé chez les animaux) [source].
Conclusion
Concernant la distinction entre intelligence humaine VS animale VS artificielle, on pourrait distinguer deux conceptions :
dichotomique : il y aurait une intelligence spécifiquement humaine, qui n'est pas de même nature que celle des animaux ou des robots ;
la distinction de nature entre intelligences humaine et animale n'est pas très populaire dans la mouvance "wokiste", pour des raisons qui me paraissent moins scientifiques qu'idéologiques [exemple].
en continuum : l'intelligence serait une notion commune aux humains, animaux et machines, mais à des échelles (intelligence humaine supérieure à celle des animaux, et potentiellement inférieure à celles des robots ?).
Différentiels de performance entre humains. Selon la psychologue et chercheuse en science cognitive Fanny Nusbaum , la performance ne serait qu'un « état », que certains ont plus de facilité à atteindre que d’autres, mais qui peut concerner quasiment tout le monde, pour peu qu’on se mette dans les bonnes dispositions [source].
L’éthologue Cédric Sueur propose une troisième approche, considérant l’intelligence animale ou les intelligences animales dans leur singularité – chaque espèce réagit avec ses propres contraintes et dans son propre milieu (*) –, sans chercher à les comparer d’un point de vue qualitatif avec l’intelligence humaine, ni à établir une nouvelle hiérarchie au sein du règne animal.
(*) Par exemple, des oiseaux réagissent positivement au test du miroir, utilisé pour juger de l’aptitude à la conscience de soi, mais pas les chiens. Or, ce dispositif fait appel uniquement au sens de la vue, et des tests du même ordre adaptés au sens de l’odorat ont montré que les chiens y réagissent positivement…
« L’intelligence n’est pas obligatoirement une question de degrés, mais peut se déployer selon des actions et des modes divers » souligne l'éthologue [source]. C'est dans ce contexte que la notion de sentience conduit à la proposition de reconnaître aux animaux une personnalité juridique de personnes physiques non humaines [source].
Humain vs machine
2. Émotion
3. Transhumanisme
4. Paradoxe de Moravec
Subjectivité
La subjectivité est une caractéristique qui différencie les humains (et probablement l'ensemble du règne animal) des machines (du moins jusqu'à nos jours, nous y reviendrons plus loin).
Pour cerner la notion de subjectivité, analysons la différence entre information (données) et savoir (connaissance) :
Information (données) : les données ou l'information se réfèrent généralement à des faits, des observations ou des éléments concrets. Elles sont souvent considérées comme objectives car elles peuvent être mesurées, vérifiées et partagées de manière relativement impartiale. Cependant, la collecte, le traitement et la présentation des données peuvent être biaisés en fonction des choix de collecte, de la méthodologie et de l'interprétation. Les données brutes en elles-mêmes sont neutres, mais la manière dont on les utilise peut être subjective.
- Savoir (connaissance) : la connaissance implique généralement une compréhension plus profonde et une interprétation des informations, notamment par leur contextualisation. Elle est influencée notamment par l'expérience, la perspective, ou encore la culture.
D'autre part, la subjectivité peut jouer un rôle positif dans le développement de la connaissance :
créativité : la subjectivité peut stimuler la créativité, et partant susciter de nouvelles hypothèses, des théories originales et des solutions innovantes à des problèmes.
émotion et empathie : la subjectivité permet de comprendre et de ressentir les expériences des autres. Elle favorise l'empathie, qui est essentielle pour la compréhension des problèmes sociaux, culturels et humains.
moralité et éthique : la subjectivité joue un rôle central dans le développement de la moralité et de l'éthique. Les individus construisent leur compréhension de ce qui est bien et de ce qui est mal en fonction de leurs valeurs personnelles et de leurs croyances. Cela contribue à la réflexion éthique et à la prise de décisions morales.
Émotion
L'émotion est une autre caractéristique qui différencie les humains (et probablement l'ensemble du règne animal) des machines.
Si l'impulsivité et l'émotivité extrêmes risquent de nous faire prendre de mauvaises décisions, la seule rationalité peut nous y pousser tout autant. Ainsi les travaux d'Antonio Damasio auprès de personnes souffrant de lésions au niveau du lobe frontal du cortex cérébral, ayant pour effet de supprimer toute émotion, ont montré que ces personnes n'étaient plus aptes à prendre de bonnes décisions [source].
On peut définir l'intelligence émotionnelle comme la capacité à percevoir, comprendre, gérer et exprimer ses propres émotions, ainsi que celles d'autrui, afin de résoudre les problèmes et réguler les comportements liés aux émotions [source].
Quelques réflexions concernant l'émotion :
l'intelligence émotionnelle et relationnelle peut être utilisée aussi bien à des fins bienveillantes que malveillantes (cf. les pervers narcissiques).
ce que l'on appelle (abusivement ?) "l'intelligence artificielle" pourrait être capable de percevoir, et peut-être même d'interpréter les émotions des humains avec plus d'acuité que les humains eux-mêmes.
les deux points ci-dessus illustrent la nécessité d'un contrôle démocratique des moyens de production et de diffusion des savoirs (ce qui est loin d'être le cas, étant donné la sur-dominance de l'entreprise privée états-unienne Google dans le développement de l'IA).
Transhumanisme
Le transhumanisme est un ensemble de techniques et de réflexions visant à améliorer les capacités humaines, qu'elles soient physiques ou mentales, via un usage avancé de nanotechnologies et de biotechnologies. Cette notion très à la mode décrit en réalité une évolution qui a commencé avec l'invention des premiers outils, il y a plus de cinq mille ans. Les nanotechnologies et biotechnologies permettent aujourd'hui d'intégrer des outils dans le corps humain, jusqu'à modifier son code génétique (ce qui est déjà le cas d'une partie de l'alimentation industrielle, végétale ou animale).
On notera qu'une évolution inverse est déjà en train de prendre forme, c'est "l'humanisation" psychique de certains robots, qui ressemblent de plus en plus à des humains, aussi bien au niveau physique que psychique (notamment par des formes de subjectivité voire même d'émotion *).
(*) Rien n'empêche un ingénieur inventif de configurer un robot de telle façon que ses fonctionnalités soient modulées en réaction à "la vue" d'un paysage ou de "l'écoute" d'une musique, et de qualifier cette réaction de "émotionnelle".
De manière générale, il importe de ne persister dans une voie de R&D spécifique que si son ratio avantages/inconvénients a des chances substantielles de s'avérer favorable dans un délai raisonnable. L'évaluation de ce ratio doit prendre en compte les effets sur le psychisme des individus (cf. l'addiction numérique, et le stress informationnel), l'environnement, et la consommation énergétique [source].
Ainsi, alors que l'industrie pharmaceutique est parmi les plus polluantes, on notera la capacité des animaux à identifier des remèdes médicinaux de façon instinctive, et par conséquent très peu consommatrice d'énergie. D'autre part, nous verrons que l'efficacité énergétique de l'IA est très inférieure à celle des humains. Le tableau suivant illustre la thèse d'un classement inverse entre efficacités fonctionnelle et énergétique des animaux (A), humains (H) et robots (R).
| Efficacité fonctionnelle | Efficacité énergétique | |
|---|---|---|
| 1 | R | A |
| 2 | H | H |
| 3 | A | R |
Neutraliser le technologisme. En aval de la R&D, les humains ont encore la possibilité d'adapter leur mode de vie. Par exemple, j'ai banni la télévision et je n'ai pas remplacé mon gsm basique par un smartphone. Et, dans une démarche plus proactive, j'ai remplacé le système d'exploitation de mon ordinateur par Linux-Debian (en outre, j'ai conçu un système d'aide gratuite à la libération des ordinateurs familiaux : linux-debian.net).
Paradoxe de Moravec
Dans les années 1980, Hans Moravec soulignait que nos capacités de perception et de motricité nous semblent plutôt faciles et intuitives (comme la marche ou la reconnaissance d’objets) mais sont très difficiles à reproduire sous la forme d’intelligences artificielles tandis que des tâches cognitives de haut niveau (comme des calculs mathématiques complexes) sont très faciles pour elles [source]. Nous verrons que l'IA a aujourd'hui comblé ce déficit, mais au prix d'une gigantesque et croissante consommation d'énergie.
Éthique
Quels philosophes ont-ils associé l'intelligence au bien ?
Extraits de la réponse de chatGPT (janvier 2024) :
Platon (427-347 av. J.-C.) associait l'intelligence à la sagesse et à la recherche de la vérité. Dans ses dialogues, il mettait l'accent sur la connaissance et la compréhension comme éléments essentiels pour atteindre le bien
Aristote (384-322 av. J.-C.) développait la notion de phronesis, une forme de sagesse pratique, liant l'intelligence à la prise de décision éthique et à la recherche du bien commun.
John Stuart Mill (1806-1873), en tant qu'utilitariste, associait l'intelligence à la capacité de maximiser le bonheur et de minimiser la souffrance. Selon lui, une utilisation éclairée de l'intelligence devait conduire à des actions favorables au bien-être général.
Ces philosophes ont chacun apporté leur perspective unique sur la manière dont l'intelligence peut être liée à la poursuite du bien, que ce soit à travers la connaissance, la moralité, le bonheur ou le respect de la vie.
Déclin ?
Depuis le début du siècle, le QI baisse ... en Occident, de sorte qu'aujourd'hui le QI moyen est de seulement 98 en France et aux USA, contre 108 à Hong Kong et Singapour. Une des causes pourrait être la qualité et les budgets de l'enseignement, plus élevés dans les pays asiatiques [source]. Une étude plus récente suggère un éventail plus large de facteurs explicatifs : déclin des valeurs éducationnelles, dégradation des systèmes éducatifs et scolaires, télévision et médias, dégradation de l'éducation au sein des familles, dégradation de la nutrition, dégradation de la santé [source], mais confirme le rôle prépondérant de l'éducation. Ces études sont cependant contestées par d'autres chercheurs selon qui, si l’on prend en compte l’ensemble des données internationales, il n'y aurait pas de baisse mais plutôt stagnation, qui pourrait s'expliquer par l'approche de limites intrinsèques à l’espèce humaine [source].
Intelligence collective
2. Local vs global
3. Auto-organisation
4. Émergence
5. Liberalisme : marchés efficients ?
6. Théorie des jeux
7. Classe dirigeante
8. Contrôle des moyens de production
9. Dynamique collaborative
10. Projets
Introduction

Un exemple d'application de l'intelligence collective humaine est notre méthodologie visant à organiser la collaboration d'un millier de groupes constituants, pour concevoir et développer collectivement un système de DD, en mettant en place les conditions d'une dynamique d'auto-organisation et d'émergence (/groupes-constituants).

Photographie d'un flocon de neige [source].
L'auto-organisation est une caractéristique de l'intelligence collective. Elle n'est pas celle-ci, puisque le phénomène d'auto-organisation est observé également dans le monde non-vivant. Un exemple emblématique d'auto-organisation dans le monde du non-vivant est la structure (symétrique) d'un flocon de neige. Ses six branches constituant un hexagone sont caractéristiques de la structure cristalline de la glace. Au niveau microscopique chaque molécule d'eau est composé d'un atome d'oxygène entouré de deux atomes d'hydrogènes, formant un V autour du premier. Au niveau macroscopique, chaque branche est une fractale c-à-d que la structure de ses composants est invariable quel que soit le niveau d'échelle de l'observation.
Si l'on accepte l'hypothèse que l'intelligence existe en tant que caractéristique propre aux organismes vivants, alors il est de même pour l'intelligence collective.
Les images ci-dessous illustrent des formes simples d'intelligence collective, observées dans le monde animal. Elles ont en commun deux faits troublants : (i) elles s'expriment au travers de formations, composées des corps d'individus d'une même espèce, et (ii) ces formations présentent toutes une forme de symétrie, laquelle remplit une fonction précise.

Formations d'oiseaux en vol, pour minimiser leur consommation d'énergie. |

Formation de poissons, pour se protéger de prédateurs. |

Formation de fourmis, constituant un pont. |
Nous développons ici la thèse selon laquelle l'intelligence collective humaine consisterait en l'exploitation – consciente et proactive – des phénomène d'auto-organisation et d'émergence, par des intelligences individuelles communiquant via un réseau "le plus décentralisé possible".
On devine déjà ici l'importance du contrôle démocratique de l'infrastructure – matérielle et électronique – du réseau ...
Local vs gobal
Le passage conceptuel entre les dimensions individuelle et collective de l'intelligence correspond à la question fondamentale, dans le domaine scientifique, du lien entre niveaux local et global.
1. Physique quantique2. Conscience non localisée ?
3. Réseau décentralisé
Physique quantique
Dans l'état actuel des connaissances en physique, les lois naturelles qui régissent la physique des corps microscopiques (disons de taille inférieur à l'atome), semblent différentes de celles observées au niveau macroscopique. Le tableau suivant synthétise le principe d'incertitude (ou d'indétermination) d'Heisenberg, à savoir que la perception que nous avons du monde microscopique ne peut être exprimée (mesurée) qu'en termes probabilistes, c-à-d qu'il existe une incertitude – certes limitée (inférieure à 100 %), mais systémique (inhérente aux corps microscopiques) – quant à la connaissance que nous avons de la position ou de la quantité de mouvement d'une particule (NB : cela n'implique nullement que, dans la réalité, une particule pourrait être dans plusieurs positions ou états en même temps).
Données de la mesure d'un électron
| Micro | Macro | |
|---|---|---|
| Position | incertaines si état connu | certaines |
| État | incertains si position connue | certains |
"Incertaine" ≡ probabiliste.
- Question à chatGPT : l'affirmation suivante est-elle correcte ? : "La théorie quantique ne dit pas que la physique des corps microscopiques serait d'une nature différente de celle des corps macroscopiques, mais seulement que la mesure des phénomènes physiques à l'échelle microscopique ne peut être que de nature probabiliste".
- Réponse de chatGPT (extrait) : "La physique quantique ne se limite pas seulement à l'aspect probabiliste. Elle introduit également des concepts et des phénomènes tels que la dualité onde-particule ou encore l'intrication quantique (...) et d'autres aspects qui ne sont pas simplement une conséquence de la probabilité, mais qui remettent en question notre compréhension classique de la physique".
Quelques remarques :
Déterminisme. Soulignons que le principe d'incertitude est inhérent à la nature microscopique. Il n'est donc pas lié à une insuffisance des technologies actuelles de mesure. Autrement dit, contrairement au monde macroscopique, la physique microscopique est par nature soumise à une part de hasard, ce qui semble remettre en question le principe de déterminisme.
- Machines quantiques. Cependant, il existe des effets quantiques au niveau macroscopique, par exemple des résonateurs mécaniques dans une "superposition d’états" [source].
Discontinuité. Si la physique microscopique est qualifiée de mécanique quantique, c'est en raison d'une discontinuité inhérente à cette dimension, illustrée notamment par le fait qu'un électron ne peut se situer qu'à certaines orbites autour de son noyau.
Passons maintenant au corps vivants.
Conscience non localisée ?
Des scientifiques ont suggéré que la thèse selon laquelle le siège de la conscience est le cerveau des individus pourrait être incomplète. Ils suggèrent que les consciences individuelles seraient reliées par une conscience collective, de sorte que la conscience "individuelle" dépasserait spatialement voire aussi temporellement le corps (cf. notion de "conscience non-localisée" proposée par le cardiologue Pim van Lommel : source ; approfondir : scholar.google.com/scholar?q=nonlocal+consciousness).
Réseau décentralisé
Quoi qu'il en soit, il est incontestable qu'une forme de conscience collective existe déjà, et se développe depuis que les humains construisent des moyens de communication (routes, écriture, Internet, ...). Internet est un réseau de communication virtuelle, c-à-d limitée aux seules données sous forme de bits. En outre, Internet intègre des unités de stockage (bases de données) et de traitement de ces données (requêtes, calcul, affichage sous diverse formes, ...).
Ainsi en combinant, au sein d'un protocole tel que Ethereum, des chaînes de blocs (bases de données distribuées sur un réseau pair-à-pair) avec des contrats intelligents, on peut constituer des applications décentralisées (dApp) telles qu'une organisation autonome décentralisée ("DAO") ;
De nombreuses applications pourraient fonctionner sur un réseau tel que Ethereum : gestion d'identité et de réputation, traçabilité des produits alimentaires, location d’appartements ou de voitures, bornes de ravitaillement électrique, achat de crédit d’énergie, instruments financiers auto-exécutifs, enchères, marchés de prédiction, etc. Les DAO sont notamment supposées réduire les coûts de vérification, d’exécution, d’arbitrage et de fraude [source].
Approfondir :
La dynamique d'intégration des sphères locales à la sphère globale, exprime sa potentialité dans le phénomène d'émergence, que l'on résume souvent par l'idée selon laquelle "le tout vaut plus que la somme des parties". Mais avant d'aborder la notion d'émergence, traitons une autre notion caractérisant l'intelligence collective : l'auto-organisation.
Auto-organisation
2. Structures dissipatives
3. Imprévisibilité
Définition
Je définirais l'auto-organisation, dans le monde du vivant, donc dans la sphère sociologique, comme étant le phénomène par lequel un groupe d'individus mènent des actions qui, vues de l'extérieur peuvent paraître coordonnées, alors qu'en réalité ces actions individuelles sont le fait d'individus qui ne se connaissent pas nécessairement, et peuvent même ignorer l'existance des autres membres du groupe informel qu'ils constituent (et qu'ils constituent sans le savoir nécessairement !). L'apparence de coordination est simplement la conséquence d'intérêts partagés entre les membres de ce groupe informel.
On notera que la méconnaissance du phénomène d'auto-organisation peut expliquer la propension de nombreuses personnes à interpréter des faits politiques ou économiques en termes complotistes. Autrement dit, ces personnes voient des complots même là où il n'y en a pas nécessairement !
Structures dissipatives
L'explication des intérêts partagés fonctionne pour le monde du vivant, et en l'occurrence pour des organismes qui ont une volonté. Elle n'est donc pas applicable pour expliquer l'auto-organisation dans le monde du non-vivant (cf. flocon de neige). Pour cela il faut se référer à la notion de "structures dissipatives" mises en évidence par Ilya Prigogine, qui fut professeur à l'université libre de Bruxelles et prix Nobel de chimie en 1977. On parle de structure dissipative dans le cas d'un système ouvert ne pouvant subsister dans un état stationnaire que s'il est traversé par des flux d'énergie. Une structure dissipative est donc un système hors équilibre : son énergie interne peut certes rester constante en moyenne (comme dans un système fermé) mais elle est constamment renouvelée (contrairement à un système fermé).
Approfondir : allocation-universelle.net/thermodynamique#structure-dissipative
Per Bak a montré que l'auto-organisation relève d'un processus qu’il a baptisé "criticalité auto-organisée" par lequel les structures dissipatives s'organisent à la manière des transitions de phase continues, comme le passage de l’état liquide à l’état solide, c-à-d au passage d’un état désordonné (l’état liquide) a un état ordonné (l’état cristallin). Des avalanches de bifurcations produisent des arborescences fractales : amplification des fluctuations ⇒ rupture de symétrie (avec invariance par changement d'échelle) ⇒ apparition et mémorisation d'information.
Les transitions abruptes nécessitent un apport extérieur d’information sous la forme d’un germe. Lors des transitions continues – cas des structures dissipatives – de l’information apparaît progressivement au fur et à mesure que la phase ordonnée se développe. Ces informations se propagent par percolation au sein de domaines d'Ising. Le modèle s'auto-organise de façon à maximiser l'énergie reçue (cf. supra les cacahuètes récompensant les essais réussis par le singe dans le modèle d'apprentissage de Bak et Stassinopoulos : #apprentissage).
Physique ⇒ biologie ⇒ sociologie. Selon François Roddier « le concept de réseau neuronal peut s’appliquer à tout système dissipatif considéré comme un ensemble d’agents échangeant de l’énergie et de l’information. On sait aujourd’hui que ces agents s’auto-organisent pour maximiser la vitesse à laquelle ils dissipent l’énergie (principe d'entropie maximale). C’est apparemment le cas des molécules d’air dans un cyclone, des bactéries dans une colonie, des fourmis dans une fourmilière comme des neurones dans notre cerveau. C’est aussi le cas des sociétés humaines. » [source].
Peut-on appliquer à tous ces phénomènes le même modèle d’auto-organisation ? Le modèle de Bak et Stassinopoulos représente un réseau régulier de neurones, mais les simulations faites avec des réseaux quelconques de noeuds reliés par des connexions arbitraires fonctionnent également. Le modèle de Bak et Stassinopoulos permet donc de modéliser la dynamique cognitive d'une population, dont chacun des individus peut échanger de l'information avec n'importe quel autre et déclencher une action. On peut alors parler d'intelligence collective ou de "cerveau global" [source].
Selon Roddier, en biologie l'ontogenèse correspondrait à une transitions abruptes, et la phylogenèse à une transition continue. L’information est mémorisée dans les gènes. Les êtres vivants qui partagent les mêmes gènes forment des domaines d’Ising appelés espèces animales ou végétales. Chez l’homme, l’information est principalement mémorisée dans son cerveau. Les sociétés humaines mémorisent à leur tour de l’information dans les livres, plus récemment dans les ordinateurs. C’est ce qu’on appelle la "culture". Les individus qui partagent la même culture forment des domaines d’Ising sous la forme de sociétés humaines. Les lois de la thermodynamiques expliquent donc aussi le phénomène sociologique d'auto-organisation [source1, source2].
Exploitation. La notion marxiste d'exploitation des salariés est fondée notamment sur l'appropriation de la plus-value collective, cette plus-value pouvant être vue comme le fruit du phénomène d'émergence.
Le modèle peut également expliquer la dynamique du progrès scientifique : « les sociétés humaines s’auto-organisent en formant un cerveau global capable de mémoriser toujours plus d’information. Cette information leur permet de dissiper de plus en plus d’énergie. C’est ce que nous appelons le progrès scientifique et technique. (...) Un réseau neuronal reçoit de l’information de sa source froide: c’est le cas du cerveau global que forme notre société. (...) La température de cette source froide peut s’exprimer en euros dépensés par bits d’information mémorisée. Cela soulève le problème du coût de la recherche scientifique. Plus ce coût est important, plus la température de notre source d’information est élevée et plus le rendement de Carnot de notre société est bas. (...) Les sociétés humaines s’effondrent lorsque leur rendement de Carnot est trop bas » [source].
Imprévisibilité
Une propriété importante des systèmes auto-organisé est qu'ils sont largement imprévisibles. L'auto-organisation n'est donc pas bénéfique ou vertueuse en soi. Ainsi un phénomène catastrophique peut fort bien être auto-organisé.
Moulin de fourmis (40sec)
Selon François Roddier « un système qui s'auto-organise a une évolution plus ou moins imprévisible. En effet si l'on pouvait parfaitement prévoir son évolution, celle-ci ne nous apporterait aucune information. Notre connaissance du système resterait inchangée. Le fait que son entropie diminue montre que ce n'est pas le cas : notre connaissance du système augmente. Il y a apparition d'informations nouvelles imprévues. Cela explique les difficultés des prévisions météorologiques. Cela explique aussi pourquoi le comportement des êtres vivants est largement imprévisible. L'évolution d'une société humaine l'est aussi. Au contraire, l'évolution d'un système isolé est largement prévisible : un mélange d'eau chaude et d'eau froide donne toujours de l'eau tiède [source p. 35] ».
Une question vient alors à l'esprit : le phénomène d'auto-organisation est-il suffisant en soit pour organiser efficacement la société (thèse de l'idéologie anarchiste/libérale) ? La réponse semble négative : dès lors que les phénomènes auto-organisés sont imprévisibles, comment pourraient-ils correspondent systématiquement aux besoins des humains, en tout lieu et à tout instant ? Le phénomène du moulin de fourmis évoqué plus haut illustre d'ailleurs le fait que l'auto-organisation n'est pas nécessairement rationnelle et bénéfique.
Ces faits conduisent à la question : comment organiser efficacement et durablement la société humaine ?
Émergence
L'émergence est le phénomène par lequel "le tout vaut plus que la somme de ses parties". Elle est déterminée par deux propriétés d'une population : sa taille et sa diversité.
Définir l'émergence comme le phénomène par lequel le tout vaut plus que la somme des parties peut paraître abusif dans la mesure où il ne respecte pas le premier principe de la thermodynamique ("rien ne se créé, rien ne se perd"). Cependant, le principe d'émergence ne s'applique pas à la matière ou à l'énergie, mais à des effets ou fonctionnalités, que l'on observe qu'au seul niveau global.
La vie elle-même est un processus émergent : à partir de réactions chimique, un processus d'auto-organisation conduit progressivement à l'élaboration de structures complexes.
Ainsi par exemple, des exemples d’intelligence émergente se trouvent chez les groupes d’animaux sociaux, comme les fourmis ou les abeilles, où l'on observe, à l’échelle du groupe, une forme d’intelligence qu’on ne trouve pas à l’échelle de chaque animal séparé [source].
Notons que les effets émergents ne sont pas nécessairement rationnels ou bénéfiques, comme l'illustrent les lynchages collectifs par des groupes d'humains.
Un possible contre-exemple de l'émergence est donné, selon la thèse dite du "covidisme", par le cas des experts en épidémiologie (notamment ceux de l'OMS) qui, enfermés dans leur tour d'ivoire des modèles mathématiques – nécessairement simplistes au regard de l'extrême complexité des phénomènes biologiques – ont fait imposer aux populations une stratégie "anti-épidémique", fondée sur la peur et la coercition, et dont les effets pervers sont d'une telle ampleur que ce seraient eux, et non le virus qui expliqueraient la majorité de la surmortalité toutes causes observée entre 2020 et 2022.
Cependant, au moins chez les humains, le travail de groupe peut participer à rehausser le niveau moyen de capacité de chacun des individus : ainsi par exemple, on chante plus juste à plusieurs que tout seul, car on se corrige en écoutant les autres [source]. Et cela sans aucune forme d'organisation.
La formation, l'information et l'organisation des individus peut améliorer leurs performances individuelles et collectives. Ainsi la délibération est une technique pouvant produire des effets d'émergence. Elle peut opérer comme suit [source] :
- répertorier les informations ;
- classer les arguments en "bons" et "mauvais" ;
- obtenir un consensus (et si celui-ci s'avère impossible il faut alors voter).
Landemore rappelle diverses théories éclairant le phénomène d'émergence [source], notamment en illustrant l'importance du nombre et de la diversité des membres du groupe :
- théorème du jury de Condorcet :
- thèse : plus les membres d'un groupe de votants soumis à la règle de la majorité simple seront nombreux, plus la probabilité de la vérité de la décision sera grande : la limite de cette probabilité sera la certitude (voir aussi théorème central limite) ;
- hypothèse principale : votes indépendants (pas de suivisme) ;
- miracle de l'agrégation :
- thèse : des expérimentations montrent que les réponses moyennes, d’un grand échantillons d'individus, à des questions ayant une solution vérifiable, tendent à être remarquablement correctes, car les erreurs des individus étant distribuées de manière symétrique autour de la bonne réponse, elles se compensent au niveau général ;
- hypothèse principale : distribution aléatoire des erreurs ;
- diversité cognitive :
- thèse : (i) L’erreur collective d’un groupe équivaut à l’erreur individuelle moyenne moins la diversité prédictive collective ; autrement dit, lorsqu’il s’agit de faire des prédictions, la différence cognitive entre les votants est tout aussi importante que la compétence individuelle ; (ii) le groupe fait nécessairement de meilleures prédictions que son membre moyen ; en outre, le gain en précision prédictive du groupe par rapport à son membre moyen augmente avec la diversité cognitive du groupe ;
- hypothèse principale : existence de corrélations négatives entre les modèles prédictifs des individus (sinon l'agrégation les accroît).
Diversité
cognitive
La diversité cognitive entre individus, par rapport à l'objet (physique, social, ...) étudié, est notamment fonction des capacités cognitives, méthodes, intuitions, milieu social, vécu ou encore âge respectifs. Elle se traduit par des différences dans les analyses des causes comme des effets (ainsi par exemple, une situation peut être perçue comme problématique pour certains mais pas par d'autres).
Lu Hong et Scott Page auraient établi (2004) qu’en raison des bénéfices de la diversité cognitive (c’est-à-dire la diversité des intelligences et des perspectives), des groupes non experts mais diversifiés sont souvent meilleurs, dans la résolution de problèmes complexes, que des groupes d’experts [source]. Ainsi selon Hélène Landemore : « il vaut souvent mieux avoir un groupe de personnes cognitivement diverses qu’un groupe de personnes très intelligentes qui pensent de la même manière. En effet, alors que des personnes très intelligentes qui pensent de la même manière vont avoir tendance à s’arrêter rapidement sur la solution qui leur paraît la meilleure sans chercher plus loin, les membres d’un groupe cognitivement plus divers ont la possibilité de se guider les uns les autres dans l’exploration d’autres possibilités : ils ne s’arrêtent pas à la solution commune retenue par ceux qui pensent pareillement et se donnent ainsi une chance de trouver la meilleure solution entre toutes (l’optimum global) » [source].
À cet égard il importe de distinguer :
- réductionnisme : qui réduit le complexe au simple (procédé courant dans l'enseignement et la modélisation);
- spécialisation (cas des experts) : qui développe une connaissance toujours plus complexe d'un domaine toujours plus réduit.
Dans les deux cas il y a risque de décrochage par rapport au réel, et de dérive vers le dogmatisme voire le scientisme. Dans une société qui survalorise l'expertise (c-à-d la division du travail), le suivisme peut alors conduire au phénomène du "moulin de fourmis" voire à des prophéties auto-réalisatrices (cf. le "covidisme" ?).
Ceci dit, l''émergence ne remet évidemment pas pour autant en question l'utilité des experts, notamment lors de la phase 1 de la délibération (cf. supra).
Auto-organisation
et émergence
L'émergence concerne aussi les machines, comme l'illustrent des expériences sur les automates cellulaires et la robotique en essaim. Une équipe de chercheur de l'ULB a ainsi montré que des robot peuvent, collectivement, séquencer des actions dont l’ordre d’exécution est à priori inconnu. Dans la méthode appliquée, les deux paradigmes robotiques – délibératif (sens-modèle-planifier-acte) et réactif (sens-acte) – traditionnellement considérés comme incompatibles, coexistent d’une manière particulière : la capacité de planifier émerge au niveau collectif, à partir de l'interaction d’individus réactifs. [source]. Cette expérience est particulièrement intéressante car elle décrit une dynamique "d'émergence de l'émergence", fondée sur une forme d'auto-organisation.
Dans la vidéo ci-dessous, l'épidémiologiste Didier Raoult évoque un phénomène étonnant : la somme des décisions individuelles, apparemment non concertées, de se faire tester reflète de façon très précise l'évolution statistique d'une épidémie (courbe en cloche).
Prendre en compte l'intelligence collective (juin 2020- 0m52s)
Démocratie
Il résulte de l'effet d'émergence que la démocratie pourrait s'avérer supérieure à l'oligarchie d'un point de vue épistémique. Mais qu'en est-il du passage de la démocratie représentative à directe ? Pour Landemore « il y a une limite théorique à l’augmentation de l’intelligence collective par l’introduction de toujours plus de points de vue. Dans l’agrégation de jugements, la diversité cognitive n’est pas une fonction linéaire du nombre de jugements agrégés et il y a un retour sur apport qui, au-delà d’un certain seuil, va s’amenuisant. (...) Ce problème de seuil suggère a priori la supériorité épistémique de la démocratie représentative sur la démocratie directe dans les sociétés de masse » [source].
Cette thèse de non linéarité (il y aurait un plafond) reste à prouver. Mais même en supposant sa validité théorique, il est hautement probable qu'en pratique le progrès technologique augmente constamment cette limite de sorte qu'il y a au moins linéarité. Ce progrès technique et technologique est illustré par notre méthodologie de conception et développement d'un système de gouvernance de démocratie directe (cf. /groupes-constituants), qui vise à activer les phénomènes d'auto-organisation et d'émergence, au moyen de trois principes fondamentaux : les comparaisons croisées, les validations itératives et la redondance initiale. Elle organise le travail collaboratif de plusieurs milliers de personnes, et il n'est pas évident d'identifier une limite théorique ou pratique au nombre maximum de participants ...
Médias vs réseaux sociaux : qui dit la vérité (2016, 1m5s)
Lorsqu'il s'agit de classer les causes de mortalité par ordre d'importance, les réseaux sociaux sont plus proches de la vérité scientifique que les médias "d'information". Est-ce une illustration de l'intelligence collective, ou de la propension des médias au sensationnalisme ? L'intelligence collective serait-elle plus performante sans l'influence de la presse ?
Liberalisme : marchés efficients ?
La notion économique de marché est un cas de théorie de l'auto-organisation. Selon cette théorie, chaque individu n'aurait qu'à viser la maximisation de son profit personnel pour que, via le mécanisme des marchés et des prix, s'opère une allocation – supposée optimale – de l'ensemble des biens et services. Par "optimale", on entend que cette allocation est la meilleure possible pour chacun et la collectivité. Les marchés sont ainsi supposés "efficients". Autrement dit, toute organisation des marchés par l'État serait nuisible par nature. Cependant de nombreux faits suggèrent que le postulat d'efficience naturelle des marché n'est pas pertinent (cf. allocation-universelle.net/principes-monetaires#marches-inefficients).
Dans une approche biologique, François Roddier extrapole le modèle de Bak et Stassinopoulos (cf. supra #apprentissage) à l'économie, en assimilant l'excitation des neurones à la richesse monétaire des individus. Les signaux d'entrée expriment le besoin en produits ou services. La transmission des signaux correspond à des transactions financières. En l'absence de percolation, ces transactions se limitent à des placements financiers. Lorsque le réseau percole, il conduit à une offre commerciale. Dans ce schéma, l'économie financière représente les réflexions du cerveau global. L'économie de production traduit ses actions réelles [source].
On est ici au niveau macroéconomique, mais l'économie – science de la gestion des ressources – doit également être étudiée au niveau microéconomique. À ce niveau, la théorie des jeux propose une description formelle d'interactions stratégiques entre agents (appelés « joueurs »).
Théorie des jeux
2. Jeux répétitifs
Équilibre non-collaboratif
Le dilemme du prisonnier est un fondement de la théorie des jeux. Le tableau suivant montre les règles de ce jeu, l'objectif des joueurs/prisonniers étant de minimiser leur peine, alors qu'ils ne connaissent pas la stratégie adoptée par l'autre, et n'ont pas de moyen d'influencer celui-ci.
PS : on pourrait reformuler le jeu de sorte que l'objectif est de maximiser un gain, cela revient au même.
Les règles sont les suivantes :
- si les deux accusés se chargent l'un l'autre (trahison), le juge les condamne à 5 ans chacun ;
- si les deux accusés collaborent pour se couvrir, le juge confronté au doute les condamne chacun à la peine minimale de 1 ans ;
- si l'un couvre l'autre (COL) mais que celui-ci l'accuse (TRA), le premier est condamné à la peine maximale (10 ans) tandis que le second est libéré.
On peut résumer ces règles sous forme de matrice.
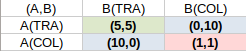
Le tableau suivant est une présentation plus intuitive.
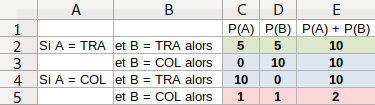
Lecture ligne 3 : si A trahit et B collabore alors A est libéré tandis que B est condamné à 10 ans de prison (NB : les joueurs ne connaissent pas le choix de l'autre).
La colonne E montre que ce jeu (i) n'est pas à somme nulle (la colonne contient des valeurs non nulles) ; et (ii) est à somme variable (les valeurs de la colonne ne sont pas identiques).
Paradoxe. Ce jeu est conçu de telle sorte que son résultat est paradoxal :
- chaque peine individuelle minimale correspond à la trahison : ce sont les cases C3 et D4 ;
- la peine collective minimale correspond à la collaboration : 2 est le minimum de la colonne E, et il correspond à la collaboration pour A comme pour B.
D'autre part, l'incertitude concernant le choix opéré par l'autre joueur (par exemple A) a pour effet (étant donné les valeurs du tableau) que :
- si A trahit, alors B minimise sa peine en trahissant (5 < 10) ;
- si A collabore , alors B minimise sa peine en trahissant (0 < 1).
On constate donc que les dans les deux cas (c-à-d quel que soit le choix fait par A) B a intérêt à trahir. Et comme les situations de A et B sont symétriques la même conclusion vaut également pour A. Chacun des deux joueurs devrait donc trahir l'autre (ligne 2). Or dans ce cas la peine obtenue ne correspond ni aux peines minimales individuelles ni à la peine minimale collective, et cela alors que le comportement des joueurs est pourtant supposé rationnel.
La cause de ce paradoxe est double : (i) les règles du présent jeu (qui en l'occurrence sont fondées sur la logique du système judiciaire) sont conçues pour inciter à la trahison ; (ii) l'incertitude quant au choix opéré par l'autre joueur conduit à minimiser le risque d'obtenir la peine maximale (c-à-d à maximiser la probabilité d'obtenir un temps libre maximum).
Stratégie dominante. Dans un jeu dont la stratégie optimale est indépendante de l'anticipation faite par le joueur quant à l'action simultanée/inconnue des autres joueurs (ici, A a intérêt à trahir quelque soit le choix fait par B), la stratégie optimale est dite "dominante".
Interprétations. Le résultat du dilemme du prisonnier requiert deux commentaires importants :
L'on pourrait très bien concevoir des jeux dans lesquels les joueurs n'ont pas d'autre choix rationnel que de collaborer (programmation du résultat théorique). On ne peut donc extrapoler le résultat du dilemme du prisonnier à tous les jeux possibles et imaginables, et conclure que le dilemme du prisonnier démontrerait que dans la vie en général les individus n'ont pas intérêt à collaborer ou ne sont pas enclins naturellement à le faire. Comprenons donc bien que le dilemme du prisonnier ne révèle absolument rien sur la nature humaine en général (*), mais par contre il nous en dit sans doute un peu sur ses concepteurs, qui ont préféré illustrer le principe de stratégie dominante par une stratégie non-collaborative plutôt que de collaborative ...
(*) Néanmoins, les expérimentations de ce jeu permettent d'évaluer la propension d'une population de joueurs à collaborer ou trahir. En l'occurrence une expérience aurait donné 20% de collaborations et 80% de trahisons. Dans une autre expérience la répartition serait plus proche de la parité (question : la plus grande proportion de collaborations s'explique-t-elle par une plus large connaissance du dilemme du prisonnier parmi les joueurs ?).
Il faut se garder d'associer systématiquement un caractère positif à la collaboration et négatif à la non collaboration (trahison) : tout est relatif au point de vue (c-à-d au référentiel). Ainsi un cartel peut maximiser ses revenus (au détriment du reste du monde ...) en convenant (i) de quotas de production et (ii) de punitions en cas de dépassement des quotas. Pour neutraliser cette collaboration l'État (ou une autorité internationale) peut par exemple assurer une quasi-immunité au membre du cartel qui révélera l'accord à la justice (trahison) et permettra ainsi de punir les autres membres du cartel [source p. 155].
Utilité/applications de la théorie des jeux :
permettre à une organisation d'influencer (programmer ?) le comportement de ses membres (NB : dans l'intérêt de la collectivité ... ou des seuls dirigeants de l'organisation) ;
Exemples :- quelles modifications apporter au mode de fonctionnement d'une organisation pour améliorer l'efficacité de la collaboration entre ses membres ?
- quels éléments du mode de fonctionnement d'une organisation non démocratique permettent-ils de neutraliser le risque de révolution démocratique ?
- indiquer aux individus quelle stratégie adopter pour minimiser les risques (maximiser les chances).
Jeux répétitifs
Si le jeu devient répétitif chaque joueur peut alors observer les choix précédents des autres joueurs, et implémenter des stratégies visant à influencer leur comportement. Selon une expérience réalisée en 1979 par Robert Axelrod, la stratégie socialement et individuellement optimale dans nos relations avec autrui est la suivante : coopérer à la première partie, puis adopter systématiquement le dernier choix fait par l'autre joueur (coopérer s'il a coopéré, trahir s'il a trahi) [source].
Selon une estimation, dans les jeux répétitifs, le pourcentage de trahisons serait proche de ... 100%, du moins lorsque les joueurs n'ont pas connaissance des conclusions d'Axelrod.
Cette stratégie dite "donnant-donnant" est de type "à mémoire courte" car elle consiste à ne tenir compte que de la dernière action de l'adversaire (coopération ou trahison) en faisant table rase du passé (même si le passé de l'adversaire n'est fait que de trahisons !).
Application. On notera que cette règle relève du bon sens et peut être appliquée aussi bien dans le travail professionnel avec les collègues que dans le travail éducatif avec les enfants (P.S. Appliquer ces conclusions exige donc de vaincre notre rancune tout autant que notre gentillesse. La raison doit l'emporter sur nos états d'âme ...). Au niveau des États, la stratégie "donnant-donnant" peut être appliquée dans la négociations des accords de libre-échange.
Encore mieux. En 2012 des chercheurs ont trouvé un type de stratégies supérieures au donnant-donnant : les stratégies "à déterminant nul". Celles-ci sont cependant éthiquement un peu plus problématiques, et cela pour deux raisons : (i) elles reposent sur un procédé statistique relativement complexe (et avantagent donc les individus capables de les comprendre/appliquer) ; (ii) elles consistent à contraindre la partie adverse. Pour ce deuxième point la problématique éthique est cependant tempérée dans la mesure où (a) il s'agirait d'une contrainte généreuse (résultat gagnant-gagnant) ; (b) dans les grandes populations qui évoluent, l'optimum ne serait plus cette contrainte généreuse, mais la coopération [source].
Une excellente vidéo de vulgarisation (14m36s) sur la théorie des jeux.
Classe dirigeante
On pourrait considérer qu'une classe dirigeante est une démocratie limitée à ses membres, ou encore que dans une démocratie directe la classe dirigeante serait constituée de l'ensemble de la population (de sorte que la notion de classe ne ferait plus sens). Dans ces phénomènes politiques et économiques la part d'auto-organisation ne doit pas être sous-estimée.
Complots ? Ainsi la réalité opérative de classes dirigeantes peut s'expliquer bien plus simplement comme relevant d'un phénomène d'auto-organisation, plutôt que d'une organisation volontariste. Les intérêts des parties prenantes – plus ou moins bien compris (l'opportunisme de certaines, la naïveté d'autres) – peuvent donner l'illusion d'une organisation concertée, alors même que ces parties ne se connaissent pas nécessairement, voire n'ont pas même conscience de l'intégralité des parties et intérêts en jeu.
Ceci dit, il est flagrant que la conscience de classe est (beaucoup) plus marquée chez les riches que chez les pauvres. Cela est probablement lié au contrôle des moyens de production de masse (MPM), notamment ceux du savoir et de la propagande. Or de la conscience de classe à l'organisation concertée il n'y a qu'un petit pas ...
Si l'auto-organisation peut expliquer l'existence de classes dirigeantes, l'organisation concertée en est une autre cause possible (et complémentaire). L'efficacité de cette organisation volontariste est illustrée par le spectaculaire développement économique de la Chine.
Eric X. Li : L'histoire de deux systèmes politiques (TED 2013, 20m37s)
Les classes dirigeantes nationales sont caractérisées par leur volonté de puissance, laquelle est à l'origine de la plupart des guerres de conquête, et cela d'autant plus qu'il est aisé aux membres de l'establishment d'échapper aux devoirs militaires dangereux. Une illustration de ces faits est la guerre du Vietnam. Quant au principe de Pax Romana il est une illusion locale dans la mesure où les guerres se déroulent en dehors des frontières, puisqu'à l'instar des entreprises privées, tout empire doit s'étendre pour ne pas disparaître.
Contrôle
des masses.
Il semble que le débat social fonctionne largement sur le mode émotionnel. Ainsi en politique et en économie, que l'on cherche à "gauche" ou à "droite", il devient de plus en plus difficile de trouver des discours qui n'exploitent pas le registre de l'émotionnel. C'est notamment le cas des débats sur le climat, l'immigration, le libre-échange ou encore l'Union européenne, où stigmatisation et moralisme confrontent leurs simplismes respectifs. Mais c'est notamment au travers de ce débat que l'intelligence collective peut opérer, pour autant que la liberté d'expression soit préservée.
Contrôle des moyens de production
La liberté d'expression n'est pas fondée que sur des considérations morales, mais aussi, et peut-être surtout, pragmatiques. Ainsi l'information libre est une condition nécessaire pour analyser correctement, et gérer efficacement, n'importe quelle situation. Un contre-exemple flagrant fut le covidisme : la liberté d'expression fut remplacée par la propagande et l'intimidation des discours contredisant la version officielle. Il en a résulté que la majorité de la surmortalité toutes causes observée en 2020 et 2021 (plus de quinze millions de décès dans le monde) fut probablement causée non par le virus mais par les graves effets pervers de la stratégie de la peur.
Le covidisme illustre la nécessité du contrôle démocratique des moyens de production de l'information et du savoir, intrants principaux de l'intelligence collective. Nous avons suggéré que ce contrôle pourrait être exercé au moyen de coopératives publiques. Malheureusement les traités de l'Union européenne découragent voire empêchent les États membres de créer des entreprises publiques et d'ainsi accroître la concurrence en proposant aux consommateurs une offre publique de biens et services.
Au moyen de coopératives publiques, l'État devrait notamment :
- éradiquer l'analphabétisme informatique en développant les capacités de production plutôt que de consommation de services & biens informatiques ;
- proposer aux consommateurs citoyens une offre alternative publique, en matière de logiciels libres et de matériels libres.
Dynamique collaborative
Frederick P. Brooks Jr., qui fut au début des années 1960 un des principaux concepteurs de l’OS 360, le système d’exploitation des mainframes IBM, il est illusoire de prétendre établir au début d’un projet un cahier des charges et des spécifications immuable dont la maîtrise d’œuvre devra assurer docilement la réalisation fidèle. Le plus difficile dans une telle entreprise consiste à définir le but à atteindre, et que l’on ne peut y arriver que par itérations successives : réalisation d’un prototype sommaire, que l’on montre au donneur d’ordres, qui fait part de ses critiques et de ses suggestions à partir desquelles sera réalisé un second prototype plus élaboré, et ainsi de suite, pendant tout le cycle de vie du système [source p.128]. Il s'agit donc d'un processus progressif et itératif, favorisant l'action a posteriori, sur la base de l'expérience, et non à priori, sur la base de spéculations [source].
Projets
Développer un concurrent de Wikipédia qui serait réservé aux personnes identifiables par une forme crédible de eID. Actuellement, les pages "Utilisateur" des éditeurs et modérateurs de Wikipédia sont des simulations d'identification (exemple), ce qui ouvre la porte au contrôle de certains sujets par des groupes bien organisés et financés.
Intelligence artificielle
2. Analogie
3. Définition
4. Materiel
5. Instructions
6. IA symbolique
7. Réseau physique
8. IA et statistique
9. Réseau de neurones artificiels
10. Bilan énergétique de l'IA
11. Risques
12. Business modèles
13. Le futur
Introduction

Entre 1970 et 2010, le nombre de transistors présents sur une puce de microprocesseur a doublé en moyenne tous les deux ans. Depuis, cette vitesse d'amélioration des performances a ralenti, en raison de limites physiques à la miniaturisation et de coûts croissants des matériaux.
Le ralentissement de la croissance des capacités du matériel ("hardware") a été compensées par des progrès substantiels au niveau des données, en termes :
- quantitatif : Internet donne accès à des quantités gigantesques de données (web des objets) ;
- qualitatif : les technique de traitements statistiques des données, notamment par la méthode des "réseaux de neurones" artificiels).
L'IA avait connu une première vague dans les années 1980 sous le nom de "systèmes experts". Il s'agissait d'une IA "symbolique", caractérisée par l’utilisation de règles logiques pour résoudre des problèmes, simulant un raisonnement déductif (exemple : si..., alors...). Peu performante dans les problématiques instables et ouvertes, elle a aujourd'hui fait place à une IA dite "connexionniste", qui se fonde sur une analyse probabiliste de données, simulant un raisonnement inductif [source]. Les ordinateurs ont ainsi acquis des capacités d'apprentissage statistique non supervisé (c-à-d sans intervention humaine pour catégoriser les données d'entrée).
Les années 2010 ont boosté l'IA, en complétant l'approche symbolique par la méthode connexionniste :
| IA symbolique | 1997 | Le superordinateur Deep Blue bat les meilleurs joueurs de jeu d'échec. |
| IA connexionniste | 2013 | Google Speech-to-Text reconnaît des sons. |
| 2015 | Le logiciel AlphaGo bat les meilleurs joueurs du jeu de Go. | |
| 2016 | Amazon Rekognition reconnaît des formes. | |
| 2023 | chatGPT est capable de soutenir une conversation qui est systématiquement cohérente ("bluffante") au niveau de la forme et du sens, et souvent cohérente au niveau du fond. |
On peut ainsi résumer les deux types d'IA, historiques et complémentaires :
l’IA symbolique :
- sélection de données par arbres de décision (minimax) ;
- traitement des données exhaustif et déductif.
l’IA connexionniste:
auto-apprentissage par renforcement, au moyen de réseaux de neurones, à partir de base de données pouvant être initialement très petites (par exemple les seules règles du jeu de Go), puis enrichies par entraînement (par exemple les résultats d'une grande série d'auto-jeux)
- traitement des données probabiliste et inductif.
Ainsi pour reconnaître un chat dans une image, l'IA symbolique nécessite des règles explicites très détaillées sur ce qui constitue un chat (forme des oreilles, présence de moustaches, etc.), tandis qu'une IA connexionniste peut apprendre à reconnaître un chat après avoir été exposée à des milliers d'images, développant sa propre compréhension des caractéristiques pertinentes.
L'IA n'est pas simplement une évolution de l'informatique traditionnelle. Elle représente un changement de paradigme où les systèmes deviennent plus autonomes et adaptatifs (capacités d'auto-apprentissage) et acquièrent des capacités nouvelles fondamentales (notamment le traitement du langage naturel et la vision par ordinateur). Ce "saut évolutionniste" fut rendu possible par les niveaux atteints en terme de capacités de collecte de données (sur Internet), de leur stockage (mémorisation) et traitement (vitesse de calcul des processeurs), et qui sont telles qu'un simple ordinateur portable dépasse aujourd'hui les capacités humaines dans un nombre croissant de fonctions cognitives.
Les progrès futurs dans l'IA résident probablement dans le développement de processeurs biologiques (moindre consommation d'énergie) et quantiques (extrêmement plus rapides).
Enfin, deux problématiques majeures de l'IA sont son énorme consommation énergétique, et un "risque existentiel " pour l'humanité.
Analogies
On pourrait oser l'analogie suivante entre informatique et humains:
| Physique | Biologie |
|---|---|
| ordinateur | os, muscles et organes |
| logiciels | cerveau |
| électricité | aliments et sang |
| bits | acides aminés (composants des protéines, molécules élémentaires) |
| réseau | la société humaine |
Il importe cependant de souligner des différences de nature fondamentales entre systèmes physiques et biologiques :
| Critères | Systèmes physiques | Systèmes biologiques |
|---|---|---|
| Composition | Matière inanimée | Matière vivante |
| Énergie | Utilisation directe | Métabolisme complexe |
| Information | Externe ou limitée | Interne (ADN) et évolutive |
| Adaptabilité | Faible | Très élevée |
| Organisation | Externe | Auto-organisée |
| Reproduction | Impossible | Possible |
| Entropie | Tendance au désordre | Maintien de l'ordre |
| Finalité | Fixée par un concepteur | Survie et reproduction intrinsèques |
Les analogies sont utiles pour favoriser la compréhension de notions nouvelles, à condition de les utiliser à bon escient. Ainsi pour voler l'homme à inventé des machines très différentes des oiseaux (leur propulsion n'est pas réalisée par le mouvement des ailes, mais par des réacteurs). Ainsi les méthodes modernes en matière d’IA tendent à se concentrer sur la division d’un problème en un certain nombre de problèmes plus petits, isolés et bien définis, et à les résoudre l’un après l’autre. Cette démarche contourne les grandes questions sur le sens de l’intelligence, de l’esprit et de la conscience, en se concentrant sur la mise en place de solutions pratiques à des problèmes concrets.
D'autre part, selon Laurent Bloch, « les travaux qui fournissent les emplois d'aujourd'hui (et fourniront plus encore ceux de demain) sont ceux qui ne peuvent se passer de l'intervention humaine, parce qu'ils font appels à l'intellection, ou à l'affectivité, ou à l'intuition, ou à une combinaison de ces trois aptitudes auxquelles ne peuvent suppléer ni les algorithmes ni même l'IA ».
Mais si l'IA parvenait à simuler l'intellection, l'affectivité et l'intuition, ne pourrait-elle pas alors simuler ce que ces aptitudes humaines permettent de réaliser ?
Bloch semble convaincu que l'IA ne pourra jamais accéder au sens des énoncés du langage, notamment parce qu' « ils sont infléchis par l'influence du contexte dans lequel ils se donnent, or le contexte est indéfini, et infini, ce sont même ses caractéristiques principales. Indéfini parce qu'il est propre à chaque individu, infini, parce qu'il se prolonge jusque dans notre inconscient, et dans celui de nos ancêtres, ainsi que dans nos expériences sensorielles les plus intimes » [source].
Définition
Dès lors qu'il n'existe de consensus scientifique sur ce qu'est l'intelligence individuelle, il en est de même pour l'IA.
Néanmoins, une possible définition [source] est qu'une machine peut être qualifiée "d'intelligente" si elle vérifie les deux propriétés suivantes :
- autonomie : capacité d’exécuter des tâches dans des environnements complexes, sans guidage constant de la part d’un utilisateur;
- adaptabilité : capacité d’améliorer les performances grâce à l’apprentissage par l’expérience.
Quant à l'incarnation physique de l'IA, c-à-d l'ordinateur, celui-ci est un "automatique programmable universel" [source].
Matériel
2. Électronique
3. Données en bits
Architecture
Machine
de Turing
En 1936 le mathématicien Alan Turing proposa un modèle théorique de calcul, développé dans le but de comprendre les limites de ce qui peut être calculé par une machine. La "machine de Turing" est constituée d’une bande infinie de mémoire divisée en cellules, une tête de lecture/écriture qui peut se déplacer sur cette bande, et un ensemble d'états qui régissent le comportement de la machine.
Détail des trois composants de la machine de Turing :
une bande infinie divisée en cellules, où chaque cellule peut contenir un symbole.
une tête de lecture/écriture qui peut lire et écrire des symboles sur la bande et se déplacer dans les deux sens.
- une table de transition qui spécifie les opérations basées sur l'état actuel et le symbole lu :
- un ensemble fini d’états parmi lesquels on distingue un état initial et les autres états, dits accepteurs ;
une fonction de transition qui, pour chaque état de la machine et chaque symbole figurant sous la tête de lecture, précise :
- l’état suivant ;
- le caractère qui sera écrit sur le ruban à la place de celui qui se trouvait sous la tête de lecture ;
- le sens du prochain déplacement de la tête de lecture.
Architecture de
von Neumann
Au début des années 1940, le mathématicien John von Neumann proposa un modèle d'architecture de calcul, avec une mémoire centrale (où les programmes et les données sont stockés), un processeur qui exécute les instructions, et une unité de contrôle qui gère l'exécution des programmes :
- Unité Centrale de Traitement (CPU) :
- unité de Contrôle : supervise l’enchaînement des instructions dans l’ordre indiqué par un programme.
- unité Arithmétique et Logique : effectue les opérations arithmétiques et logiques.
l'ALU (acronyme en anglais) contient les circuits logiques des instructions (les instructions sont des objets physiques, en l’occurrence des circuits électroniques qui réalisent ces opérations conformément aux règles de l’algèbre de Boole, qui permet de modéliser des raisonnements logiques selon un formalisme qui se prête bien à la réalisation par des circuits électroniques) [source].
- accumulateur : registre utilisé pour stocker les résultats des opérations intermédiaires.
- Mémoire :
- contient à la fois les données et les instructions.
- les adresses mémoire permettent d'accéder aux différentes valeurs stockées.
- Bus (flèches) : pour le transfert des adresses mémoire, données et signaux de contrôle.
- Interfaces d'entrée et de sortie :
- entrée : permet de recevoir des données externes (clavier, souris, etc.) qui sont stockées en mémoire ou utilisées directement.
- sortie : permet d'envoyer des données traitées à l'extérieur (écran, imprimante, etc.).
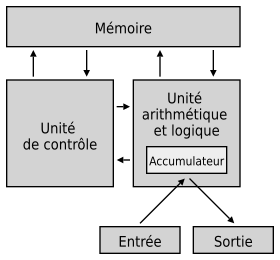
Les deux principes à la clé de l’architecture de von Neumann sont l’exécution séquentielle et le partage d’une mémoire unique pour les instructions et les données du calcul [source p.51]. Source image.
Exemple pratique : addition de deux nombres [source : chatgpt.com] :
- Saisie des données depuis l'entrée :
- L'opération 5 + 3 est introduite via un périphérique d'entrée (par exemple, un clavier).
- Ces données sont stockées dans des emplacements mémoire distincts :
• A pour 5
• B pour l'opérateur +
• C pour 3
- Chargement des données et de l'opérateur :
- L'unité de contrôle récupère l'instruction LOAD A, qui charge le nombre 5 dans l'accumulateur.
- L'instruction LOAD C est ensuite récupérée pour charger le nombre 3 dans un autre registre.
- Exécution de l'addition :
- L'unité de contrôle identifie l'opérateur + stocké dans B et commande à l'UAL (Unité Arithmétique et Logique) d'effectuer l'addition.
- L'UAL ajoute le contenu de l'accumulateur (5) avec le nombre stocké dans l'autre registre (3), en utilisant l'opérateur +.
- Le résultat 8 est stocké dans l'accumulateur.
- Stockage du résultat : l'instruction STORE D est exécutée pour stocker le résultat 8 dans l'adresse D en mémoire.
- Envoi du résultat sur le périphérique de sortie : Le résultat 8 est récupéré de la mémoire et envoyé à un périphérique de sortie (par exemple, un écran) pour être affiché.
Selon Samuel Goyet, « avant von Neumann, programmer c’était tourner des boutons et brancher des fiches dans des tableaux de connexion, depuis von Neumann c’est écrire un texte » [source, p.412, édition 2024].
Le traitement simultané de plusieurs opérations est-il possible ?
En théorie, non. En pratique, oui. Un ordinateur ne peut théoriquement traiter plusieurs instructions séparément. Cependant, en pratique, des ordinateurs à plusieurs processeurs peuvent exécuter plusieurs programmes simultanément. L'illusion de simultanéité provient du fait que pour un humain les délais d'action et de perception sont respectivement de l'ordre du dixième et centième de seconde, alors qu'un processeur peut traiter plusieurs centaines de millions d’instructions par seconde, ce qui correspond à quelques nano-secondes (milliardièmes de seconde) par instruction, soit un ordre de grandeur huit à neuf fois inférieur. Par conséquent, une tranche de temps de quelques fractions de seconde, partagée entre plusieurs processus, donne à l’échelle macroscopique de la perception humaine l’illusion de la simultanéité [source p.48].
Électronique
Le matériel informatique ("hardware") – en l'occurrence le processeur – étant composé de systèmes électroniques, il ne peut traiter et stocker que des données binaires, en l'occurrence des 1 (présence de courant) et des 0 (absence de courant). Ce matériel ne peut donc interagir qu'avec des programmes/logiciels ("software") écrits en langage binaire. Les programmes informatiques écrits par des humains doivent donc être convertis/traduis en ce langage machine pour pouvoir être exécutés par le processeur.
L’unité centrale de l’ordinateur est constituée de circuits logiques, qui réalisent matériellement les opérations de la logique, et à partir de là les opérations arithmétiques élémentaires. Un circuit logique fonctionne sur base d'un dispositif dit semi-conducteur, qui en fonction d’un courant de commande laisse passer ou bloque un courant entre une source et un collecteur [source, p.401, édition 2024]
Le transistor est un composant électronique à semi-conducteur permettant de contrôler ou d'amplifier des tensions et des courants électriques au sein d'un circuit logique.
Transistors vs neurones
L'analogie entre un neurone et un transistor réside dans leur capacité à traiter des signaux et à contrôler leur transmission. Là où les transistors gèrent des signaux électriques de manière binaire ou analogique dans les circuits électroniques, les neurones traitent des signaux chimiques et électriques dans les réseaux neuronaux biologiques :
- Traitement et Transmission des Informations :
Transistor : dans les circuits intégrés, les transistors sont assemblés en réseaux complexes pour traiter l’information sous forme de bits (0 et 1), permettant aux ordinateurs de réaliser des calculs.
Neurone : dans le cerveau, les neurones sont également interconnectés en réseaux très complexes pour traiter des informations sensorielles, motrices et cognitives, permettant au cerveau de réaliser des fonctions d'apprentissage, de mémoire et de perception.
- Trois Points de Connexion :
Transistor : un transistor a trois points de connexion principaux : l'entrée, la sortie, et la borne de commande.
Neurone : un neurone a des dendrites pour la réception d'information (équivalent à l'entrée), un axone pour transmettre le signal (équivalent à la sortie), et le soma (corps cellulaire) qui agit comme le centre de décision (équivalent de la borne de commande).
- Fonction de Contrôle du Signal :
Transistor : il agit comme un commutateur ou amplificateur de signal, contrôlant le passage du courant entre deux bornes en fonction du signal appliqué à sa borne de commande.
Neurone : le neurone reçoit des signaux d'autres neurones (par ses dendrites), intègre ces signaux, puis produit un signal de sortie (potentiel d'action) transmis via l'axone si le seuil de stimulation est atteint.
- Fonctionnement tout-ou-rien :
Transistor : dans les circuits numériques, le transistor agit souvent en mode tout-ou-rien, passant de l’état « off » (pas de courant) à l’état « on » (courant maximal), ce qui est la base des circuits logiques.
Neurone : le neurone suit aussi une logique de type tout-ou-rien pour le potentiel d’action. Lorsqu’il reçoit suffisamment de stimulation pour dépasser un seuil, il génère un potentiel d’action. Sinon, il reste « au repos », sans émettre de signal.
- Modulation de Signal :
Transistor : en mode analogique, le transistor peut amplifier les signaux faibles. La modulation de la tension ou du courant à la borne de commande permet de contrôler le flux de courant entre les deux autres bornes.
Neurone : le neurone intègre les signaux excitateurs et inhibiteurs reçus de plusieurs autres neurones. Si la somme des signaux reçus dépasse un certain seuil, il déclenche une réponse de sortie. Cette intégration et sommation de signaux est une forme de modulation de signal.
- Effet de Seuil et Filtrage :
Transistor : le transistor a un seuil de tension ou de courant à partir duquel il commence à conduire entre ses bornes principales.
Neurone : le neurone possède également un seuil d’activation pour le déclenchement du potentiel d'action, ce qui agit comme un filtre pour éviter de répondre à des stimulations faibles ou aléatoires.
Le transistor bipolaire est le plus simple. Les circuits actuels utilisent plutôt des transistors à effet de champ, qui autorisent des densités plus élevées, mais avec des circuits plus complexes,
Transistor bipolaire
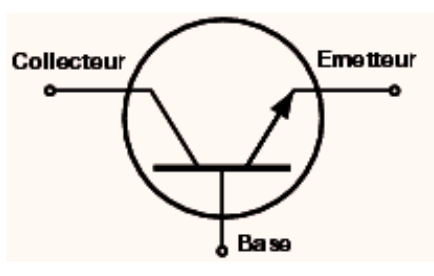
Quand la base est mise à une tension positive, le courant passe du collecteur à l’émetteur ; quand la base est mise à une tension négative ou nulle, le courant ne passe pas [source, p.401, édition 2024].
L'utilisation des transistor comme circuits logiques repose sur l'algèbre de Boole, qui repose sur deux notions :
- une épreuve (action) : par exemple tirer sur un cible ;
- un événement (résultat) : l'endroit de l'impact sur la cible :
- A : l'impact est situé dans la partie supérieure de la cible ;
- B : l'impact est situé dans la partie droite de la cible ;
Algèbre de Boole
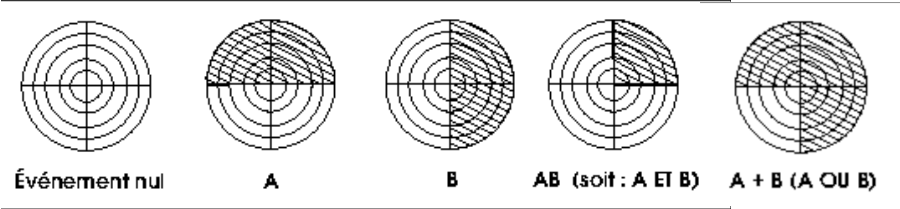
Quand la base est mise à une tension positive, le courant passe du collecteur à l’émetteur ; quand la base est mise à une tension négative ou nulle, le courant ne passe pas [source, p.403, édition 2024].
- l'événement "A et B" est noté A ∧ B ou A * B (ou AB) car correspond à un produit d'événements ;
- l'événement "A ou B" est noté A ∨ B ou A + B car correspond à une somme d'événements ;
- l'événement "non A" est noté A− : ainsi soit C = A ∨ B alors C− correspond au cadran inférieur gauche.
On introduit l'algèbre dans ces raisonnements logiques au moyen d'une table de vérité, qui consiste à attribuer à chaque résultat deux valeurs possibles :
- 1 : vrai, courant positif ;
- 0 : faux, courant nul.
| x | y | x*y | x+y |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 |
L'algèbre de Boole est numérique et logique (0 * 0 = 0), tandis que l'algèbre de l'électricité correspond à des phénomènes physiques (- * - = +).
Fonctionnement
des circuits
« Les circuits ci-dessous comportent des résistances, symbolisées par des fils en zigzag, qui comme leur nom l’indique font obstacle au passage du courant. Si le courant trouve un chemin plus facile, comme par exemple un transistor à l’état passant, il ne franchira pas la résistance (plus exactement, le courant qui franchira la résistance sera faible et inférieur au seuil qui le rendrait efficace). Mais s’il n’y a pas d’autre chemin, par exemple parce que le transistor est à l’état bloqué, le courant franchira la résistance » [source, p.404, édition 2024]..
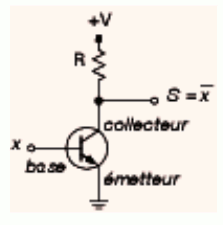
Circuit "NON". Si x=0, la base du transistor est à un potentiel nul, le transistor est bloqué ; via la résistance, le courant positif va arriver en sortie x−, qui vaudra donc 1, ce qui est bien le contraire de 0. Si x=1, le courant positif atteint la base du transistor qui devient passant. De ce fait, le point x est directement relié à la masse, donc à une tension nulle et vaudra 0, ce qui est le résultat voulu.
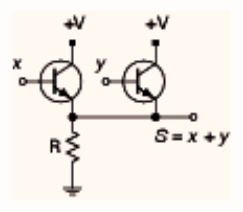
Circuit "OU". « Nous avons deux transistors en parallèle : pour que le courant positif parvienne à la sortie notée x+y et lui confère ainsi la valeur 1, ou le vrai, il suffit que l’un des deux transistors soit passant. Pour cela il suffit que l’une des deux entrées, x ou y, soit positive : en effet un courant positif en x par exemple l’emportera sur la mise à la masse générée par R. C’est bien le résultat attendu. ».
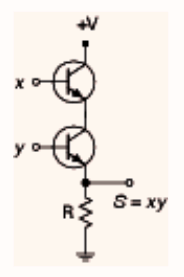
Circuit "ET". « Nous avons deux transistors en série : pour que le courant positif atteigne la sortie notée xy il faut que les deux transistors soient passants, et donc que les deux entrées x et y soient positives, ce qui est bien le résultat voulu, conforme à la sémantique du ET. ».
Laurent Bloch explique brillamment comment une position de mémoire élémentaire, qui représente un bit, est obtenue en combinant deux circuits NON OU de telle sorte que la sortie de l’un alimente l’entrée de l’autre, et réciproquement : source, p.409, édition 2024.
Loi de
Moore
Entre 1970 et 2010, le nombre de transistors présents sur une puce de microprocesseur a doublé en moyenne tous les deux ans (loi de Moore). Depuis, cette vitesse d'amélioration des performances a ralenti, en raison de limites physiques à la miniaturisation et de coûts croissants des matériaux.
Source : hardware.fr
Semi-conducteurs, transistors, circuits intégrés et microprocesseurs.
Ces quatre notions, parfois confondues, sont pourtant à distinguer : les premiers sont la base matérielle des transistors, ceux-ci sont regroupés dans des circuits intégrés et ces derniers lorsqu’ils permettent avec une unité unique de faire fonctionner un ordinateur prennent le nom de microprocesseurs.
Dès 1833, Faraday constate qu’à la différence de la plupart des métaux dont la résistance augmente avec la température, certains métaux comme le sulfate d’argent sont de plus en plus conducteurs avec la hausse de la température (coefficient de température négatif)3. Un siècle plus tard, en 1931, Wilson théorise les semi-conducteurs : les électrons forment des ondes dans les solides et la conduction électrique de certains matériaux varie en fonction de divers facteurs comme la température, le courant électrique ou la lumière.
La loi de Moore (doublement du nombre de transistors présents sur une puce de microprocesseur tous les deux ans) fut observée empiriquement jusqu’aux années 2010. La contrepartie de cette loi de Moore – fondée sur la réduction de la taille des traits gravés dans le silicium permettant d’augmenter la densité des processeurs et par conséquent leur vitesse – est la « loi de Rock » (du nom d’Arthur Rock) selon laquelle le coût d’une fonderie de semi-conducteurs double quant à lui tous les quatre ans, sous l’effet de procédés de fabrication de plus en plus chers. Cependant, le mur des limites physiques des microprocesseurs, avec le fait d’approcher de la taille moléculaire, est aujourd'hui atteint ...
Fin 2004, la première entreprise au monde (tous secteurs confondus) en terme de chiffre d'affaire est la société états-unienne Nvidia qui conçoit des puces (mais sous-traite leur fabrication à l’entreprise de fonderie taïwanaise TSMC). La production de semi-conducteurs en silicium est un marché assez monopolistique, car les coûts fixes sont prépondérants, ce qui le rapproche des conditions d’un monopole naturel.
[source].Données en bits
Pour traiter des informations, les ordinateurs doivent les convertir en données sous forme de bits. Le bit est l'unité la plus simple dans un système de numération, ne pouvant prendre que deux valeurs, désignées le plus souvent par les chiffres 0 et 1. Dans un ordinateur, c-à-d un système électronique, la valeur 1 correspond au passage d'un courant électrique (ou une tension spécifique), et la valeur 0 à son absence.
Les ordinateurs quantiques fonctionnent quant à eux à l'aide de bits quantiques, ou qubits, qui peuvent :
- exister dans des états de superposition : par exemple dans un état correspondant à 0 pour une probabilité de x %, dans un état correspondant à 1 pour une probabilité de 100-x %) ;
- être intriqués : l'état de l'un peut dépendre de l'état de l'autre, même si les deux qubits sont séparés par de grandes distances.
Grâce à ces deux propriétés, un processeur quantique peut traiter une quantité beaucoup plus grande de données, et cela en parallèle (alors qu'un processeur classique ne peut traiter les données que séquentiellement), de sorte que la vitesse de traitement d'une même quantité d'information est également beaucoup plus grande.
Nous allons ici développer quelques notions concernant la notion de bits dans le cadre des ordinateurs classiques.
Représentation informatique des nombres entiers [source, p.392, édition 2024]. Soit un ordinateur dont l’architecture matérielle met à notre diposition, pour représenter les entiers, des emplacements de n positions en base B (B étant paire). On peut alors représenter B n nombres différents. Ainsi une machine à mots de 32 bits autorisera des entiers compris entre - 232 / 2 et 232 / 2 - 1
Le plus grand nombre positif représentable a une valeur absolue plus faible de 1 que celle du plus petit nombre négatif représentable, parce que 0 est "avec" les nombres positifs.
Dans un ordinateur, un nombre négatif −p peut être représenté par le système du complément à deux, que l'on obtient en remplaçant chacun des chiffres de p par son complément à 1 (c’est-à dire en remplaçant chaque 1 par un 0 et chaque 0 par un 1) et en additionnant 1 au résultat. Prenons un exemple avec comme base B = 2 et n = 4 chiffres possibles. Ainsi le nombre +5 est représenté par les chiffres suivants : 0101 (cf. clipedia-txt.net/mesure#systemes-numerotation). Le complément à 1 de cette combinaison de chiffres nous donne : 1010. Additionnons 1 pour avoir le complément à 2 : 1011, qui représente −5 [source, p.393, édition 2024]. On a bien – en abandonnant la dernière retenue (puisque n=4) – que :
0 1 0 1 + 1 0 1 1 ----------- 0 0 0 0Étapes du calcul :
- un plus un donne deux, je pose zéro et je retiens un ;
- un de retenu plus zéro plus un donne deux, je pose zéro et je retiens un;
- un de retenu plus un plus zéro donne deux, je pose zéro et je retiens un;
- un de retenu plus zéro plus un donne deux, je pose zéro et j'abandonne la dernière retenue.
L'avantage du système du complément à deux, pour le calcul automatique, est qu'il fait l'économie du signe négatif. Pour le calcul manuel on utilise plutôt le système binaire pur ;
1 0 1 (5 en binaire) - 0 1 1 (3 en binaire) ----------- 0 1 0
Étapes du calcul :
- colonne de droite (unité) : 1 - 1 = 0
- deuxième colonne : 0 - 1
- comme 0 est inférieur à 1, on doit emprunter 1 de la colonne suivante.
- l’emprunt transforme cette colonne en 10 (ou 2 en décimal), donc 10 - 1 = 1.
- troisième colonne : après l’emprunt, cette colonne devient 0 (puisqu'on a emprunté 1), donc 0 - 0 = 0.
Gestion des
nombre
Nombre réels. Les nombres réels constituent avec les nombres imaginaire l'ensemble des nombres complexes : ℂ = ℝ +iℝ. Mais comment, dans un ordinateur, représenter les nombres fractionnaire c-à-d « avec des chiffres après la virgule » ? Dans une machine, le "nombre de chiffres après la virgule" est nécessairement limité par la taille physique des composants. C'est pourquoi les nombres fractionnaires sont représentés dans les registres des ordinateurs selon le principe de la virgule flottante, équivalente à la notation scientifique, qui consiste à écrire 197 * 106 plutôt que 197000000, selon le modèle signe × mantisse × baseexposant. La virgule flottante permet de définir une limite de l'erreur d'approximation relative d'une machine. La norme IEEE 754, qui définit différents formats (selon le degré de précision) de nombres fractionnaires, est appliquée sur la plupart des ordinateurs. Pour approfondir : clipedia-txt.net/mesure#systemes-numerotation.
La notion d'infini en informatique
L'infini est un concept mathématique (mais pas un nombre) qui est utilisé pour décrire une quantité qui ne peut être atteinte ou qui n'a pas de limite finie. Il est utilisé dans divers contextes, notamment dans les limites, les séries infinies, ou pour décrire les comportements asymptotiques.
Dans les calculs effectués par un ordinateur, l'infini n'est pas directement représenté comme un nombre concret. Ainsi en Python, on peut utiliser float('inf') pour obtenir une valeur infinie positive et float('-inf') pour l'infini négatif, et
>>> 1/float('-inf')
-0.0
plutôt que 0, car 1 / ∞ représente un comportement asymptotique, en l'occurrence proche de zéro, ce qui est représenté par 0.0 dans le système à virgule flottante.
Quant à l'expression ∞ / ∞ qui est mathématiquement une forme indéterminée, on aura :
>>> float('inf')/float('inf')
nan
Enfin :
>>> float('inf')+float('inf')
inf
https://democratiedirecte.net/intelligence#infini-informatique
Instructions
2. Systeme d'exploitation
3. Algorithme
Langages de programmation
Emmanuel Saint-James décrit la programmation comme la transmission d'un raisonnement à une machine, capable de le reproduire. Par cette reproduction l'ordinateur s'affirme comme un instrument d'objectivation du raisonnement. Il s'inscrit dans la lignée des appareils qui ont permis de passer de l'expérience empirique à l'expérimentation scientifique : l'informatique se distingue des mathématique par un outil d'expérimentation permettant d'observer, vérifier, réfuter un raisonnement [source].
Cette transmission d'un raisonnement à une machine s'effectue par le truchement d'un langage : l'ordinateur a un langage en lui, constitué d'instructions qui effectuent des opérations sur des données. Les instructions ne font pas que désigner une action, elles l'effectuent (opération d'exécution). Les instructions sont des objets physiques, en l'occurrence des circuits électroniques qui réalisent ces opérations conformément à l'algèbre de Boole. Le langage constitué des circuits électroniques est appelé "langage machine" [source]..
Turing
Le modèle théorique de la "machine de Turing" forme avec le λ-calcul la base de la théorie des langages de programmation.
Un processeur quelconque est caractérisé par le jeu des actions élémentaires qu’il est capable d’effectuer. Ces actions élémentaires sont appelées les primitives du processeur ("instructions machine"). Un programme pour un processeur de von Neumann est une suite de primitives du processeur destiné à l’exécuter. Chacune de ces instructions élémentaires correspond à un circuit logique du processeur considéré. L’ensemble des instructions machine et des règles de leur rédaction constitue le langage machine. Pour construire toutes les combinaisons possibles de primitives, il suffit à l'unité centrale du modèle de von Neumann de pouvoir [source p.29] :
- enchaîner deux primitives;
- répéter un primitive;
- choisir entre deux primitives selon le résultat d'un test.
« Un langage qui satisfait à toutes ces conditions est dit Turing-équivalent. C’est le cas des langages de programmation généraux, tels que C, Java, Lisp ou Fortran, mais il y a des langages non-Turing-équivalents et néanmoins très utiles, comme le langage SQL d’accès aux bases de données, HTML et XML pour décrire des documents, etc » [source].
Mathématiques
vs informatique
Laurent Bloch définit la notion de traitement de l'information comme étant une « manipulation symbolique composée d’opérations de traduction et de réécriture ». Un traitement d'information est ainsi l'équivalent informatique de la notion mathématique de calcul. L'informatique c'est donc des mathématiques appliquées par des machines. On appelle ainsi procédure effective, la suite des opérations concrètes par lesquelles s’effectue un calcul, c-à-d la suite des opérations qui à partir de certaines données produiront certains résultats, constituant ainsi un traitement. C’est pour définir sans ambiguïté des procédures effectives que Turing a imaginé la machine de Turing. En particulier, les étapes du calcul/traitement doivent être enregistrées dans une mémoire. Ainsi la machine de Turing formalise les opérations de consultation et d’affectation de la mémoire. Le calcul sera terminé lorsque la mémoire sera dans un état qui contienne le résultat recherché. La mathématique ignore cette notion d’état, aspect physique qui caractérise l'informatique [source].
Le processus informatique d’affectation « opère une rupture radicale entre vision mathématique et vision informatique du calcul, elle y introduit un aspect dynamique, actif et concret qui est étranger aux mathématiciens. L’affectation (...) permet de modéliser un calcul par des états de mémoire successifs, bref c’est elle qui permet de réaliser des machines de Turing » [source p.83].
Ainsi l'expression i = i + 1 est fausse en mathématique, mais en informatique elle est correcte si le langage prévoit que le signe "=" n'exprime pas une égalité mais une affectation : i qui valait x vaut maintenant x+1. L'égalité pouvant être exprimée, en informatique, par le signe == (notamment en Python) ou === (notamment en JavaScript).
Selon Laurent Bloch, « un énoncé mathématique est essentiellement déclaratif (le "quoi"), il décrit les propriétés d’une certaine entité, ou les relations entre certaines entités. Un programme informatique est essentiellement impératif (ou performatif, le "comment"), il décrit comment faire certaines choses. Il est fondamentalement impossible de réduire l’un à l’autre, ou vice-versa, ils sont de natures différentes. Il est par contre possible, dans certains cas, d’établir une relation entre le texte d’un programme et un énoncé mathématique, c’est le rôle notamment des systèmes de preuve de programme » [source, p.413, édition 2024].
Une autre différence entre informatique et mathématique réside dans la notion d'erreur. Les erreurs de programmation se distinguent des erreurs de calcul ou de logique qui peuvent affecter une démonstration mathématique. Ainsi en informatique on peut distinguer trois types d'erreur [source] :
- les erreurs de programmation :
erreurs de syntaxe : mais le compilateur la détectera généralement et donnera des explications qui aideront à sa correction) ;
erreurs de sémantique : le programmeur a mal compris le manuel du langage, et il écrit un texte dont il pense qu’il va donner le résultat voulu, alors qu’il va donner un autre résultat, ou un programme faux, qui ne se termine pas, ou qui se termine par une erreur explicite. Les méthodes de preuve de programmes ne pourront aider que dans certains cas assez particuliers, parce qu’elles sont trop lourdes pour être appliquées à l’ensemble d’un programme (un système d’exploitation général comprend plusieurs plusieurs millions de lignes de texte, plusieurs dizaines de millions si l’on y inclut les interfaces graphiques interactives).
les erreurs techniques : l’exécution d’un programme informatique peut échouer pour une raison qui n’est pas à proprement parler une erreur de programmation mais liée au contexte technique. Ainsi, un programme qui écrit des données sur disque peut échouer si le disque est plein. La saturation de la mémoire est une autre cause d’échec courante. En principe ces circonstances sont prévisibles par celui qui lance le programme, mais pas par celui qui l’écrit.
Système d'exploitation
Un logiciel, ou programme informatique, est un fichier constitué de commandes/instructions que l'ordinateur applique pour traiter des données, interagir avec un utilisateur ou encore contrôler du matériel.
Les logiciels se divisent généralement en deux grandes catégories :
- les logiciels applicatifs – comme les navigateurs, les éditeurs de texte ou encore les jeux vidéo – servent directement à l’utilisateur pour accomplir une tâche.
-
les logiciels systèmes constituent le système d'exploitation (SE : Windows, macOS, Linux, ), qui est l'ensemble des programmes dont un ordinateur a besoin pour fonctionner (démarrage, gestion de la mémoire, des matériels périphériques, etc.).
L'utilisateur avancé peut interagir avec le SE au moyen d'applications (interfaces graphiques) spécifiques ou directement via des commandes dont l'ensemble est appelé shell. Ces commandes peuvent être combinées pour constituer des algorithmes (on dit aussi routines ou programmes) qui automatisent certaines procédures.
Le bloc "Utilisateur" du schéma ci-dessus doit être interprété au sens large, c-à-d y compris d'autre utilisateurs sur le réseau auquel il est connecté. Le schéma suivant illustre la connexion de l'ordinateur au réseau.
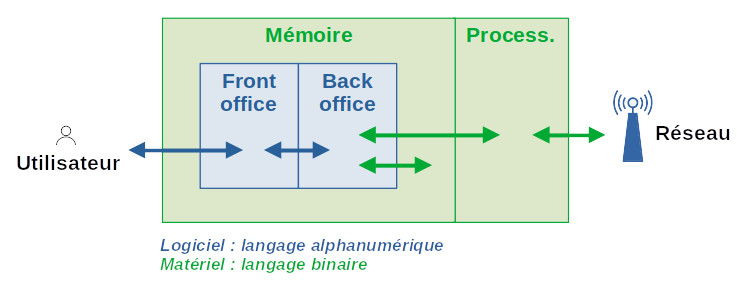
Le schéma ci-dessus inclus également des notions non mentionnées dans le schéma précédent : la mémoire et le processeur de l'ordinateur, éléments fondamentaux de son architecture (cf. supra #IA-architecture-materielle), et qui permettent d'illustrer la différence entre langages alphanumérique (ou "utilisateur") et binaire (ou "machine").
- le langage alphanumérique est utilisé par les humains pour écrire des programmes ;
- ceux-ci doivent ensuite être traduits en langage binaire, pour pouvoir être utilisables par le processeur.
Traduction
La traduction entre langage alphanumérique (flèches bleues du schéma supra) et langage binaire (flèches vertes) peut se faire de deux façons : interprétation ou compilation. L'interprétation va traduire en temps réel à chaque fois que l'application sera lancée chez l'utilisateur, alors que la compilation traduit une seule fois en amont chez le développeur :
langage interprété :
processus : le code source est traduit en langage machine à la volée par l'interprète pendant l'exécution, sans générer de code binaire complet précompilé.
avantage : le même code source peut être utilisé sur tous les types d'ordinateurs ... équipés de l'interprète approprié (un logiciel).
inconvénient : tendance à être plus lent en raison de la traduction en temps réel.
exemple : les interpréteurs JavaScript, comme ceux intégrés dans les navigateurs web, exécutent le code JavaScript des pages web.
langage compilé :
processus : le code source est entièrement traduit en un code objet en langage machine (code binaire) avant l'exécution par le processeur.
avantage : rapidité d'exécution, car le code binaire est prêt à être exécuté directement par le processeur (notion de "fichier exécutable").
inconvénient : un même code source doit être compilé pour chaque type d'ordinateur (c-à-d du type de processeur et de système d'exploitation).
Interprétation vs compilation
Il y a donc un compilateur pour chaque type spécifique d'ordinateur (X86, ARM, ...). Autrement dit, pour fonctionner sur un autre type de processeur, un programme compilé doit être recompilé pour ce type d'ordinateur.
Commentaires :
Interprétation (gauche). Même si un langage interprété ne produit pas de code binaire natif avant l'exécution, les instructions doivent toujours être exécutées en langage machine car c'est la seule forme que le processeur peut comprendre. La différence réside principalement dans le moment et la méthode de traduction par rapport aux langages compilés. En résumé, les langages interprétés sont exécutés sans passer par une compilation préalable en code machine binaire, mais ils sont traduits en instructions machine au moment de l'exécution par l'interprète.
Compilation (droite). Avant de traduire le code source en code assembleur, le compilateur procède à une optimisation du code source. D'autre part, le compilateur peut directement générer du code machine (ou du bytecode, comme en Java), mais souvent il génère du code assembleur intermédiaire.
- Mixte. Certains langages, comme Java, utilisent une combinaison des deux approches (compilation en bytecode et interprétation par une JVM avec optimisation JIT). Ce modèle permet une portabilité élevée, mais introduit des vecteurs d'attaque spécifiques, notamment au niveau de la JVM.
Plus on monte dans la hiérarchie des langages, plus on gagne en abstraction, moins on a à s'occuper du fonctionnement physique de l'ordinateur, et plus les programmes peuvent fonctionner indifféremment sur des ordinateurs de types différents. Mais cette abstraction a un prix qui se paie en efficacité. Et pour écrire les programmes du système d'exploitation, qui établissent le lien entre ce que perçoivent les programmeurs et ce qui se passe dans les circuits, on aura toujours besoins de langages de bas niveau, tels que C, Rust ou même des langages assembleurs [source].
Selon Laurent Bloch, le SE est sans doute l'objet le plus technique de notre époque. De surcroît il doit évoluer en permanence. Chaque jour arrivent sur le marché de nouveaux matériels tels que les cartes graphiques, caméras, disques durs, mémoire Flash, qui nécessitent l'écriture de nouveaux pilotes. L'apparition de nouveaux virus et la découverte de nouvelles failles de sécurité obligent à corriger le SE [source].
Menaces sur l'informatique libre
Les fabricants de matériels informatiques tentent d'accaparer du pouvoir commercial en déplaçant de plus en plus de contrôle vers du logiciel gravé dans la carte-mère, c-à-d en déplaçant les fonctions du SE de la partie "Mémoire" vers la partie "Processeur" dans le schéma ci-dessus. Ce faisant, les fabricant réduisent dangereusement le contrôle que peut exercer l'utilisateur sur son ordinateur via le SE. Ils se justifient en arguant que cela augmenterait la sécurité de l'ordinateur ...
- approfondir : /informatique-libre#logiciel-materiel-donnees
- réagir : /informatique-libre#action-citoyenne
https://linux-debian.net/citoyennete-numerique#menace-informatique-libre
Algorithme
Un algorithme est un ensemble d'instructions permettant de réaliser un objectif c-à-d résoudre un problème.
Principes élémentaires de la résolution de problèmes :
- États : situation actuelle du système ou du problème (notamment variables globales et locales).
- Entrées et sorties : entrées ⇒ traitement ⇒ sorties :
- entrées : état de départ du système ou des données ;
- sorties : état souhaité ou la solution du problème ;
- fonctions ...
Règles : conditions et contraintes à respecter ⇒ l'espace des états (leur nombre) est limité.
Modélisation : il s'agit de décomposer le problème en modules (abstraction), généralement sous forme de graphes (par exemple un arbre de décision), dont les noeuds sont les états, et les liens entre eux sont les transitions d'états (PS : le nombre et la structure des noeuds est déterminée par l'énoncé et les règles qu'il induit). À chaque noeud une valeur est attribuable.
Traitement : la résolution du problème consiste alors à identifier parmi les transitions d'état le chemin qui conduit à l'état final dont la valeur est la plus élevée (gain) ou la plus basse (coût). L'algorithme permet d'automatiser ce travail au moyen de diverses opérations informatiques :
- conditions (if/else) ;
- boucles (for/while) ;
- fonctions ...
Exemple : algorithme Minimax.
- Approches :
déterministe : les mêmes entrées produisent toujours les mêmes sorties (typiquement le cas de l'IA symbolique).
heuristique : lorsque le nombre d'états est trop élevé par rapport aux capacités de calcul disponible, on peut réduire l'espace des états au moyen de règles empiriques ou d'approximations, et ainsi obtenir rapidement des solutions "assez bonnes" ;
- probabiliste lorsque les transitions entre états ne sont pas déterministes, ou lorsque les informations sur les états/transitions ne sont pas parfaites.
Les algorithme de résolution de problèmes complexes c-à-d à grand nombre de variables (états, noeuds) et à relations (transitions d'état) non déterministes devront combiner les approches heuristique et probabilistes.
De nombreux problèmes peuvent être formulés comme des problèmes de recherche ou encore de planification.
Souvent, il existe de nombreuses manières de résoudre un problème, certaines pouvant être préférables en termes de temps, d’effort, de coût ou d’autres critères. Différentes techniques de recherche peuvent aboutir à des solutions différentes.
On peut également classer les problèmes selon leur type, comme par exemple :
- la recherche et la planification en milieu statique, avec un seul «agent» ;
- les jeux à deux joueurs («agents») en concurrence l’un avec l’autre.
L'algorithme Minimax, correspond aux jeux déterministes (pas d'éléments de hasard, tels qu'un lancé de dé), à deux joueurs, à information parfaite (à tout moment, les deux joueurs connaissent complètement l'état du jeu, il n'y a pas d'informations cachées ou secrètes (comme dans le poker, où les cartes des adversaires sont cachées) et à somme nulle (le gain d'un joueur correspond exactement à la perte de l'autre, contrairement au dilemme du prisonnier).
Comme le dit fort bien Laurent Bloch, « un programme est un texte qui décrit les opérations qui mènent des données aux résultats. La programmation est proprement magique : il suffit de soumettre ces phrases à l'ordinateur pour qu'elles déclenchent des actions. Ains, dire c'est faire, ce qui relève d'un pouvoir divin » [source].
IA symbolique
L'IA "symbolique", développée dans les années 1980, est caractérisée par l’utilisation de règles logiques pour résoudre des problèmes, simulant un raisonnement déductif (exemple : si..., alors...). Elle est peu performante dans les problématiques instables et ouvertes.
Pour reprendre les notions du triangle sémiotique de la linguistique (signifiant, signifié, objet : source), « l’IA symbolique ne dispose que du signifiant auquel elle associe éventuellement un objet mais elle est incapable de prendre en considération le signifié du mot, les concepts lui restent totalement étrangers, aussi, elle manipule les symboles sans avoir aucune idée de ce qu’ils sont, sans les comprendre pourrait-on dire » [source].
Réseau physique
Après que l'IA symbolique eut atteint son apogée dans les années 1980, le développement d'Internet à partir des années 1990 va donner accès à des quantités gigantesques de données. D'autre part, pendant ces deux décennies, la capacité de calcul des processeurs a augmenté exponentiellement. Suite à ces deux évolutions, tout était en place dès les années 2010 pour que l'IA connexionniste, née avec l'IA symbolique dans les années 50, prenne la première place.
Et l'IA connexionniste est fondée sur la notion de probabilité ...
IA et statistique
2. Probabilité conditionnelle
3. Optimisation par recuit simulé
4. Régression linéaire
5. Méthode du plus proche voisin
6. Optimisation de modèle
7. Régression logistique
L'apport des probabilités à l'IA
Les méthodes statistiques permettent d’étendre l’intelligence artificielle (IA) à :
- des problématiques complexes, c’est-à-dire lorsque les variables sont nombreuses et que leurs relations ne sont pas entièrement déterministes ;
- la gestion de l’incertitude, lorsque l’information disponible est imparfaite (incomplète ou erronée).
Pour ce faire, la statistique utilise des outils mathématiques pour extraire de l’information à partir d’échantillons et de quantifier l’incertitude, ce qui est essentiel pour construire des algorithmes d’apprentissage automatique (machine learning). Ainsi l’IA repose largement sur des modèles statistiques pour apprendre à partir de données, identifier des tendances et faire des prédictions.
Il existe de nombreuses méthodes d'IA selon le type de fonction cognitive que l'on souhaite simuler. Ainsi la régression permet de prédire une valeur continue comme par exemple le prix d'une maison, tandis que dans la classification, le résultat est une étiquette choisie parmi un ensemble fini d'alternatives, par exemple malade ou en bonne santé.
Probabilité conditionnelle
Or on peut utiliser les probabilités pour raisonner, c'est-à-dire pour déduire une chose d'une autre. Cela est basé sur la probabilité conditionnelle, c-à-d la probabilité que se produise l'événement A lorsque l'événement B s'est produit (ou que A soit vrai lorsque B l'est aussi). Autrement dit, P(A|B) = x % signifie que x % des événements où B est vrai vérifient également A [source].
Une méthode pour comprendre intuitivement la signification de la probabilité conditionnelle consiste à utiliser la notion d'ensembles : la probabilité d'être à la fois dans les ensembles A et B, c'est la probabilité d'être dans l'ensemble A fois la probabilité d'être dans l'ensemble B étant donné qu'on est déjà dans l'ensemble A :
P(A∩B) = P(A) * P(B|A) ⇔
P(B|A) = P(A∩B) / P(A) ⇔
P(B|A) = P(B∩A) / P(A)
Interprétation : la probabilité de B étant donné A c'est la probabilité de A et B divisée par la probabilité de A.
Une autre approche intuitive consiste à montrer que la probabilité conditionnelle permet d'exprimer une probabilité simple P(A) comme une moyenne de probabilités conditionnelles P(A∣Bi), pondérées par les probabilités des conditions P(Bi), qui forment une partition (somme égale à 1) : soit P(S) la proportion d'étudiant qui réussissent leur examen (S pour "succès"), P(R) la proportion d'étudiant ayant révisé, et R− l'événement "pas de révision" ⇒ :
P(S) = P(S|R) * P(R) + P(S|R−) * P(R−)
Interprétation : la proportion d'étudiants qui réussissent c'est la proportion de ceux qui ont révisé, pondérée par la probabilité de réussir étant donné qu'on a révisé, plus la proportion de ceux qui n'ont pas révisé, pondérée par la probabilité de réussir étant donné qu'on a pas révisé.
Le théorème de Bayes exprime P(A|B) comme fonction de P(B|A), P(A) et P(B) : P(A|B) = P(B|A) * P(A) / P(B) . Nombreux sont les étudiants qui ne le comprennent pas intuitivement car nombreux sont les manuels de statistiques qui ne prennent pas le temps d'expliquer comment on arrive à cette formule. Nous allons tenter ici d'y remédier.
Théorème
de Bayes
L'objectif initial est de mettre à jour la probabilité d'un événement A en tenant compte d'une nouvelle information P(B) (ce que certains scientifiques appellent abusivement "prédire A"). On veut donc trouver une fonction F telle que P(A)post = F[ P(B) ] et que l'on va noter P(A|B). Mais pour ce faire, il est plus intuitif de commencer par raisonner en terme de cote plutôt que de probabilité :
- Probabilité(A) = #A / ( #A + #B )
où B = A− - Cote(A) = #A / #B
Proportion et probabilité
Si on lance une pièce de monnaie 100 fois et qu'on obtient 55 fois "pile", la proportion observée (ou fréquence observée) de "pile" est 55/100=0,55.
La probabilité théorique d'obtenir "pile" avec une pièce équilibrée est 0,50 même si les observations ne correspondent pas exactement à cette valeur.
La loi des grands nombres établit un lien entre probabilité et proportion : lorsque le nombre d'observations tend vers l'infini, la proportion observée converge vers la probabilité théorique.
Il est facile de montrer que la cote d'un événement c'est le ratio entre la probabilité que l'événement se produise et la probabilité qu'il ne se produise pas :
#A / #B =
[ #A / ( #A + #B ) ] / [ #B / ( #A + #B ) ] =
P(A) / P(A−) =
P(A) / ( 1 - P(A) )
Soit B l'événement observé pour mettre à jour P(A) ⇒
- B|A est appelé "test vrai positif" ;
- B|A− est appelé "test faux positif" ;
- RV = P(B|A) / P(B|A−) est appelé "ratio de vraisemblance de A".
Soit Cant. la cote de A antérieure à l'obtention de l'information P(B), alors la cote de A postérieure :
Cpost. = Cant. * RV ⇔
P(A|B) / ( 1 - P(A|B) ) = P(A) / ( 1 - P(A) ) * P(B|A) / P(B|A−) ⇔
P(A|B) = P(B|A) * P(A) * ( 1 - P(A|B) ) / ( 1 - P(A) ) / P(B|A−) ⇔
P(A|B) = P(B|A) * P(A) * ( 1 - P(A|B) ) / ( 1 - P(A) ) * P(A−) / P(B∩A−) ⇔
P(A|B) = P(B|A) * P(A) * ( 1 - P(A|B) ) / P(B∩A−) ⇔
P(A|B) = P(B|A) * P(A) * ( 1 - P(A|B) ) / P(A−∩B) ⇔
P(A|B) = P(B|A) * P(A) * ( 1 - P(A|B) ) / P(B) / P(A−|B) ⇔
P(A|B) = P(B|A) * P(A) / P(B)
qui est la formulation traditionnelle du théorème de Bayes.
Interprétation. B peut être le test sérologique attestant d'une probable infection, ou encore la présence de nuages dans le ciel le matin, présageant d'une possible journée pluvieuse. Mais B ne garantit pas la certitude : il peut y avoir des nuages sans pluie, et un test peut être positif malgré l'absence d'infection (faux positif). Le théorème de Bayes permet de quantifier la variation d'incertitude concernant l'événement A, suite à l'information apportée par l'événement B, en multipliant la cote antérieure de A par le rapport entre la probabilité de vrai positif P(B|A) et probabilité de faux positif P(B|A−) .
La qualité de l'information apportée par le théorème de bayes est dépendante de la mesure dans laquelle la cote antérieure décrit la réalité ...
Application. La règle de Bayes peut être utilisée pour concevoir un filtre qui trie les emails reçus (pour les envoyer soit dans la boîte "Réception" soit dans la boîte "Pourriel") en identifiant des caractéristiques typiques des spams (notamment, ils comprennent souvent le mot "acheter"). Il suffit de calculer les rapports de vraisemblance des principaux mots d'un message, puis de les multiplier à la cote antérieure (par exemple 1:1) : la cote postérieure, après un premier mot, devient la cote antérieure pour le mot suivant, et ainsi de suite. Il suffit alors de déterminer un pourcentage au-delà duquel la cote postérieure classe un message comme spam ("dans x% des cas, un message contenant ces mots est un spam") [source].
PS : maintenant vous comprenez pourquoi il arrive régulièrement que des courriels sont classés par erreur comme spams ...
Optimisation par recuit simulé
Pour illustrer la notion d'optimisation, ainsi que la méthode du recuit simulé, imaginons que notre objectif est de secouer la surface bosselée du schéma ci-dessous de sorte que la balle située dans l'optimum local D (un creux mais pas le plus bas) se retrouve dans l'optimum global B (le creux le plus bas)..

Si vous secouez doucement la surface, il est peu probable que la balle s'échappe de sa position initiale D. Si vous donnez à la surface une seule secousse très forte, la balle rebondira de manière aléatoire puis roulera en bas de la colline jusqu'à un optimum local qui peut ou non être l'optimum global B.
La stratégie de secousse la plus rationnelle pour faire atterrir la balle au point le plus bas B, consiste à secouer la surface de façon continue mais avec une force décroissante. En commençant par de fortes secousses, la balle rebondira d'abord de manière aléatoire, mais ensuite, à mesure que vous réduirez la force, plus la position de la balle sera basse, moins il sera probable qu'elle rebondisse au-dessus des « barrières » élevées autour des optima locaux.
Notez que dans l'exercice ci-dessus, l'optimum est de type minimal, mais on pourrait imaginer un exercice où l'objectif est d'atteindre le maximum global. Supposez que la boule soit un randonneur situé dans n'importe lequel des minima locaux, dont la vue des sommets lui est cachée, et qui peut juste choisie de grimper vers la gauche ou vers la droite. Et bien la méthode du recuit simulé propose une règle permettant d'atteindre le sommet le plus élevé ... avec une probabilité "acceptable".
La méthode du recuit simulé est remarquablement simple. Au lieu d'autoriser uniquement les changements qui améliorent la solution (le randonneur monte vers un sommet), certains changements qui la dégradent (descente vers un creux) sont également autorisés avec une certaine probabilité. L'acceptation d'un « mauvais » état permet alors d'explorer une plus grande partie de l'espace des états et tend à éviter de se contenter d'un optimum qui n'est que local.
Mathématiquement, la méthode consiste à sélectionner chronologiquement des valeurs St selon la règle P ≤ exp( (St - St-1) / T ) où
- St - St-1 est le pas de chaque étape ;
- T est la "température", comprise entre 1 et 0, commence à T=1 et diminue à chaque étape, par exemple selon la règle Ti+1 = λ * Ti avec λ < 1 (par exemple λ=0.99) ;
- P est la probabilité d'accepter une St inférieure à St-1.
Fonction exponentielle [source].
La probabilité d'autoriser une transition vers le bas dépend donc de deux choses : la quantité de descente (la différence avec la position précédente retenue) et ce que l'on appelle une « température ». Ainsi lorsque lorsque St < St-1) ⇔ St - St-1 < 0) ⇒ plus ( St - St-1 ) / T diminue avec T ⇒ moins on acceptera un St inférieur. L'idée est de commencer à une température élevée pour que les changements soient plus ou moins aléatoires, mais de diminuer progressivement la température pour qu'à terme, la probabilité de descendre devienne infime.
Ainsi l'animation suivante montre qu'à des températures élevées, l'optimum global peut-être atteint mais que l'on y reste pas, tandis que plus la température est basse moins il est probable d'échapper à l'optimum global lorsqu'on s'en est approché.
Régression linéaire
La régression linéaire peut être utilisée pour "prédire" (évaluer), par exemple, le prix d'une maison (y) à partir d'un nombre limité d'observations : superficie (x0), et distance au plus proche voisin (x1) :
x = [95, 15] c = [3000, 100] y = c[0]*x[0] + c[1]*x[1] print(y) # Résultat : # 286500
On comprend intuitivement que le travail de conception du modèle – c-à-d d'apprentissage, dans le cas où cette conception est réalisée par IA – consiste en l'identification pertinente des variables explicatives xi et de leur coefficient ci.
Pour estimer les ci, il nous faut une série de yj pour des xij correspondants. Vu qu'un modèle ne reproduit que partiellement la complexité de la réalité, deux maisons (réelles) qui correspondent à une même série d'input xi pourront avoir deux prix observés différents. Ou encore, même si le prix augmente généralement avec la superficie, il peut arriver qu'une surface plus grande correspond à un prix inférieur malgré que les autres variables explicatives du modèle sont identiques.
Il existe plusieurs raisons pour lesquelles les modèles ne capturent généralement pas parfaitement le phénomène sous-jacent :
- bruit : perturbations aléatoires et non systématiques ;
- variables confondantes : caractéristiques associées à la fois aux entrées et aux sorties ;
- biais de sélection : certains points de données sont plus susceptibles de se retrouver dans les données utilisées pour construire le modèle que d'autres.
Cela nécessite de comprendre le contexte dans lequel le modèle est utilisé et les biais possibles dans les données !
L'estimation des paramètres dans la régression linéaire est l'un des problèmes classiques des statistiques et de l'apprentissage automatique, et la solution la plus classique à ce problème classique est la méthode dite des moindres carrés proposée par Legendre et Gauss au début des années 1800. La raison pour laquelle cette méthode est appelée "moindres carrés" est qu'elle consiste à sélectionner la série de coefficients qui minimise les différences au carré entre valeurs calculées vs observées de la variable de sortie du modèle.
Et pour ce faire l'utilisation de matrices est très pratique, et d'autant plus que le module numpy de Python réduit le travail à une douzaine de lignes :
import numpy as np x = np.array([ [25, 2, 50, 1, 500], [39, 3, 10, 1, 1000], [13, 2, 13, 1, 1000], [82, 5, 20, 2, 120], [130, 6, 10, 2, 600] ]) y = np.array([127900, 222100, 143750, 268000, 460700]) c = np.linalg.lstsq(x, y, rcond=None)[0] np.set_printoptions(precision=1) print(c) print(x @ c) # Résultat : # [3000. 200. -50. 5000. 100.] # [127900. 222100. 143750. 268000. 460700.]
Le code ci-dessus est l'occasion de préciser des notions très importante de modélisation, celles de variables explicatives vs dépendante, et de valeurs observées vs calculées : la matrice x montre que le modèle est composé de 5 variables explicatives (les colonnes) et de 5 séries de valeurs observées de ces variables explicatives (les lignes). La longueur de la matrice des valeurs calculées de la variable dépendante y est évidemment égale au nombre de lignes de la matrice x.
En anglais, et dans le contexte des modèles d'IA, les variables explicatives sont généralement appelées "input" (ou encore "features" et "predictors") et la variable dépendante "output" (ou encore "targets").
On notera que les valeurs calculées correspondent exactement à celles observées. Le lecteur est invité à vérifier dans sa console que cela est toujours le cas tant que le nombre de séries observées est inférieur ou égal au nombre de variables qui les composent (autrement dit, tant que le nombre de lignes de la matrice x est ≤ au nombre de ses colonnes).
numpy.linalg.LinAlgError: Incompatible dimensionspuisque les valeurs de y sont les combinaisons linéaires de x @ c ⇔ le nombre de ligne de x c'est le nombre de "colonnes" de y.
Optimisation
du modèle
L'optimisation d'un modèle vise à ce qu'il "généralise bien". Un modèle généralise bien lorsque sa précision (pourcentage de prédictions correctes) n'est pas substantiellement modifiée par son application à des données nouvelles (données de test). Si elle est substantiellement réduite, il faut à nouveau optimiser le modèle.
En augmentant le nombre de cas observés (lignes de x), on peut obtenir plus d'information sur la distribution réelle des données. Ces informations permettrons d'adapter la valeur des coefficients, et éventuellement d'ajouter ou retirer des variables explicatives, pour optimiser le modèle.
Avant de développer cette notion d'optimisation, illustrons comment procéder pour importer des données dans un modèle. Vous pouvez lire un fichier CSV (un format standard pour les données tabulaires) avec la fonction np.genfromtxt(datafile, skip_header=1). Cela renverra un tableau numpy qui contient la matrice x dans les colonnes précédant la dernière, et les données de la variable dépendante dans la dernière colonne.
# Importation module Python :
import numpy as np
# Importation fichier données entraînement :
input_file = "input_file.csv"
# Contenu input_file.csv :
# x1 x2 x3 x4 x5 y
# 25 2 50 1 500 127900
# 39 3 10 1 1000 222100
# 13 2 13 1 1000 143750
# 82 5 20 2 120 268000
# 130 6 10 2 600 460700
# 115 6 10 1 550 407000
# Lecture données entraînement :
data = np.genfromtxt(input_file, skip_header=1)
x = data[:, :-1] # Toutes les colonnes sauf la dernière
y = data[:, -1] # Dernière colonne
# Calcul coefficients :
c = np.linalg.lstsq(x, y, rcond=None)[0]
# Affichage résultats :
np.set_printoptions(precision=1) # Ajustement précision virgule pour lisibilité :
print(c)
print(x @ c)
# Résultat :
# [2989.6 800.6 -44.8 3890.8 99.8]
# [127907.6 222269.8 143604.5 268017.6 460686.6 406959.9]
Maintenant que nous savons comment ajouter des données à notre modèle pour l'optimiser, précisons ce que l'on entend pratiquement par "optimiser un modèle" : il s'agit de maximiser sa précision, ce qui requiert de mesurer celle-ci.
On mesure la précision du modèle en comparant les valeurs calculées de la variable dépendante y à celles observées, et cela à partir de deux types d'échantillons de valeurs observées des variables explicatives :
échantillon d'entraînement (matrice x_train ci-dessous), à partir duquel les coefficients sont optimisés (par exemple par la méthode des moindres carrés) ;
échantillon de test (matrice x_test ci-dessous), différent des données d'entraînement, et dont la comparaison des valeurs observées de la variable dépendante avec les valeurs calculées de cette dernière permet de mesurer la précision du modèle.
# Importation modules Python : import numpy as np # Importation fichiers données : train_file = "train_file.csv" test_file = "test_file.csv" # Contenu train_file.csv : # x1 x2 x3 x4 x5 y # 25 2 50 1 500 127900 # 39 3 10 1 1000 222100 # 13 2 13 1 1000 143750 # 82 5 20 2 120 268000 # 130 6 10 2 600 460700 # 115 6 10 1 550 407000 # Contenu test_file.csv : # x1 x2 x3 x4 x5 y # 36 3 15 1 850 196000 # 75 5 18 2 540 290000 # Lecture données entraînement : train_data = np.genfromtxt(train_file, skip_header=1) x_train = train_data[:, :-1] y_train = train_data[:, -1] # Calcul coefficients : c = np.linalg.lstsq(x_train, y_train, rcond=None)[0] # Lecture données test : test_data = np.genfromtxt(test_file, skip_header=1) x_test = test_data[:, :-1] # Affichage résultats : np.set_printoptions(precision=1) # Ajustement précision virgule pour lisibilité print(c) print(x_test @ c) # Résultat: # [2989.6 800.6 -44.8 3890.8 99.8] # [198102.4 289108.3]
Exercice. Remplacez une série de test par une série d'entraînement : l'ouput correspondant est-il alors différent de l'output observé ?
Comme son nom l'indique, la régression linéaire n'est pas adaptée pour modéliser des phénomènes non linéaires. Il existe heureusement des modèles de régression non linéaire (polynomiale, exponentielle, spline, réseaux de neurones, etc.), mais une solution plus simple peut s'avérer satisfaisante dans certains cas : la méthode du plus proche voisin, qui ne fait aucune hypothèse forte sur la forme de la relation entre les variables (pas de fonction explicite ⇒ pas de paramètres à estimer, sauf un "hyperparamètre" : le nombre de voisins pris en compte).
Méthode du plus proche voisin
Cette méthode est basée sur la proximité des observations dans l'espace des caractéristiques. Pour une nouvelle donnée, la méthode trouve les k points les plus proches dans l’ensemble d’apprentissage, et attribue à cette donnée :
- en classification (variable dépendante catégorielle) : leur classe majoritaire ;
- en régression (variable dépendante numérique) : leur moyenne ou médiane.
Variables catégorielles
Une variable catégorielle prend un nombre fini de valeurs distinctes représentant des catégories ou des groupes :
- nominales (pas d'ordre entre les catégories) ; exemples :
- couleur : {Rouge, Bleu, Vert}
- type de véhicule : {Voiture, Moto, Camion}
- ordinales (ordre entre les catégories) ; exemples :
- taille de vêtement : {S, M, L, XL}
- niveau d’éducation : {Primaire, Secondaire, Universitaire}
Remarques :
- Une catégorie correspond à un type de relation entre les valeurs.
Certaines variables catégoriques peuvent être encodées numériquement (ex. : S=1, M=2, L=3) mais restent catégoriques car elles représentent des groupes et non des quantités mesurables.
Vectorisation
La vectorisation permet de transformer des variables catégorielles en représentations numériques, et d'ainsi quantifier la proximité sémantique d’un objet (une variable) par rapport à un autre.
"Chat" ⇒ [1, 0, 0]
"Chien" ⇒ [0, 1, 0]
"Oiseau" ⇒ [0, 0, 1]
Chaque vecteur indique la présence (1) ou l'absence (0) de la catégorie correspondante.
import pandas as pd
data = {'animal': ['Chat', 'Chien', 'Oiseau', 'Chien', 'Chat']}
df = pd.DataFrame(data)
df_vec = pd.get_dummies(df, columns=['animal'])
print("Données initiales :",df)
print("\nDonnées après One-Hot Encoding :",df_vec)
# Résultats :
# Données initiales :
# animal
# 0 Chat
# 1 Chien
# 2 Oiseau
# 3 Chien
# 4 Chat
# Données après One-Hot Encoding :
# animal_Chat animal_Chien animal_Oiseau
# 0 1 0 0
# 1 0 1 0
# 2 0 0 1
# 3 0 1 0
# 4 1 0 0
Ainsi, en exprimant les localisations dans un système de coordonnées cartésiennes, le théorème de Pythagore nous dit que les distances peuvent alors être calculées en additionnant les carrés des différences entre les coordonnées x et y, et en prenant la racine carrée de la somme :
DA,B = √ [ (xA−xB)2+(yA−yB)2 ] (distance euclidienne)
En Python :
D = math.sqrt((x_A−x_B)**2 + (y_A−y_B)**2)
Distance euclidienne

De la même manière, nous pourrions calculer la différence ou la « distance » entre la maison 1 (surface=3434 m2, distanceVoisin=10 m) et la maison 2 (surface=4949 m2, distanceVoisin=50 m) en considérant les deux variables explicatives comme les "coordonnées" des maisons :
DA,B = √ [ (34−49)2+(10−50)2 ] (distance euclidienne)
En Python :
x1 = [34.0, 10.0] x2 = [49.0, 50.0] D = math.sqrt((x1[0] - x2[0])**2 + (x1[1] - x2[1])**2)
Mathématiquement, chaque série de variables explicatives xi est un vecteur. En termes de codage, ce sont des listes ou des tableaux unidimensionnels.
La méthode du plus proche voisin fournit ainsi une technique de prédiction qui n'est pas fondée sur la régression linéaire. Ainsi dans l'algorithme suivant, le prix des deux séries de test n'est pas calculé par régression linéaire (NB : aucun coefficient n'est mentionné), mais en identifiant la série de l'échantillon d'entraînement dont chacune de ces deux série de test est la plus proche. La valeur observée de la variable dépendante lui est alors attribuée.
Les fonctions spécifiques de la bibliothèque numpy nous permettent de faire tout cela en quelques lignes de code.
import math
import numpy as np
x_train = np.array([
[25, 2, 50, 1, 500],
[39, 3, 10, 1, 1000],
[82, 5, 20, 2, 120],
[130, 6, 10, 2, 600]])
y_train = [127900, 222100, 268000, 460700]
x_test = np.array([
[115, 6, 10, 1, 560],
[13, 2, 13, 1, 1000]])
for test_item in x_test:
distances = np.sum((x_train - test_item) ** 2, axis=1)
nearest_index = np.argmin(distances)
print(y_train[nearest_index])
# Résultat :
# 460700
# 222100
Optimisation du code. À la ligne 5 on ne calcule même pas la racine carrée car, étant une fonction monotone, elle ne change pas le résultat de la sélection de la valeur minimale, opérée à la ligne suivante. On réduit ainsi le temps de calcul, ce qui peu s'avérer utile lorsque la dimension du tableau x_train dépasse une certaine taille.
- Pour tester ou expliquer du code il peut-être plus simple de simuler l'importation de données :
x_train = np.random.rand(4, 5) x_test = np.random.rand(5)
PS : on aura évidemment un résultat différent à chaque exécution du code puisque les données sont aléatoires.
À priori, le résultat (1) apparaît de façon intuitive en comparant x_test à la seconde ligne de x_train : les variables explicatives sont effectivement assez proches (N.B. : l'indice 1 correspond bien au second élément car en informatique l'indexation commence à partir de zéro).
Cependant, la pertinence de notre algorithme de sélection est critiquable en termes économiques : si l'on trouvait une maison correspondant à la maison test son prix serait probablement plus proche de la première maison, car leurs surfaces sont plus proches, et la surface est la variable explicative principale dans le prix d'une maison. Le résultat de notre algorithme illustre une limitation de la distance euclidienne : alors que le premier critère (surface) varie entre 13 et 130, le dernier varie entre 120 et 1000, de sorte que celui-ci va être surdéterminant mathématiquement alors qu'il est peut-être le moins déterminant économiquement. Autrement dit une différence de 100 m entre les distances au voisin est relativement moins importante qu'un différence de 100 m2 entre les surfaces (et c'est sans parler des différences induite par les unités utilisées, par exemple des pieds au lieu de mètre dans les pays anglo-saxons). Le fait que les variables explicatives utilisent la même échelle biaise donc le résultat de l'algorithme.
Quelques solutions pour neutraliser cette limitation de la distance euclidienne :
utiliser la distance de Manhattan d(A,B)= ∑|Ai−Bi| plutôt que la distance euclidienne d(A,B)= √ [ ∑(Ai−Bi)2 ], afin de réduire l'ampleur du biais ;
mettre les valeurs des données d'entraînement à la même échelle (normalisation) de manière à ce qu’elles aient le même poids dans le calcul de la "distance".
MinMaxScaler est un outil Python de prétraitement, pour mettre à l'échelle les données dans une plage spécifique (par exemple, entre 0 et 1).
Modèles
de langage
Les modèles de langage naturel mesurent la "distance" entre deux phrases : il s'agit d'identifier parmi un échantillon de phrases d'entraînement celle dont une phrase de test est la plus proche. sur base du nombre d'occurrences des mots. Pour vectoriser un phrase, une méthode consiste à calculer la fréquence de ses mots (ceux-ci jouent donc le rôle des variables explicatives utilisées pour déterminer le prix d'une maison). En effet, ce qui distingue une phrase parmi d'autres, ce sont souvent les mots qui y sont les fréquents, mais rares dans les autres phrases.
Plus précisément, la valeur d'un mot serait sa fréquence dans une phrase, relativement à sa fréquence dans le texte constitué par les phrases. Une méthode pour ce faire est TF-IDF ("term frequency-inverse document frequency"), qui consiste à appliquer plus de poids aux mots moins fréquent selon la règle : poids = ft × log(1/fd) où:
- fréquence du terme (ft) : nombre d'occurrences divisé par la longueur du document ;
- fréquence du document (fd) : nombre de documents dans lesquels chaque mot apparaît, divisé par le nombre total de documents.
Humpty Dumpty sat on a wall Humpty Dumpty had a great fall all the king's horses and all the king's men couldn't put Humpty together again
L'algorithme suivant calcule la distance (de Manhattan) la plus proche entre des séries de mots (les phrases) dont les valeurs sont les fréquences tf-idf des mots qui les constituent.
N.B. Dans la terminologie tf-idf, chaque phrase est un "document", et leur ensemble est appelé "corpus".
import numpy as np
import math
text = '''Humpty Dumpty sat on a wall
Humpty Dumpty had a great fall
all the king's horses and all the king's men
couldn't put Humpty together again'''
def main(text):
# 1. Séparer texte en documents (lignes) et convertir les mots en minuscules :
docs = [line.lower().split() for line in text.split('\n')]
N = len(docs) # Nombre total de documents
# 2. Liste des mots du corpus :
vocabulary = list(set(word for doc in docs for word in doc))
# 3. Calculer la fréquence des termes (TF) et la fréquence des documents (DF)
tf = {} # Une liste par document
df = {} # Une liste par document
for word in vocabulary:
tf[word] = [doc.count(word) / len(doc) for doc in docs]
df[word] = sum(1 for doc in docs if word in doc) / N
# 4. Construire la représentation TF-IDF pour chaque document :
tfidf_vectors = []
for doc_index in range(N):
vector = []
for word in vocabulary:
idf = math.log(1 / df[word], 10)
tfidf_value = tf[word][doc_index] * idf
vector.append(tfidf_value)
# Arrondir chaque valeur du vecteur TF-IDF à trois décimales :
tfidf_vectors.append([round(x, 3) for x in vector])
# 5. Créer une matrice pour stocker les distances entre les documents :
dist = np.empty((N, N), dtype=float)
# Calcul distance Manhattan :
for i in range(N):
for j in range(N):
if i == j:
dist[i, j] = np.inf # Ignorer la comparaison d'un document avec lui-même
else:
diff = [abs(a - b) for a, b in zip(tfidf_vectors[i], tfidf_vectors[j])]
dist[i, j] = sum(diff)
# 6. Trouver la paire de documents la plus similaire (distance minimale) :
nearest_pair = np.unravel_index(np.argmin(dist), dist.shape)
# Afficher les vecteurs TF-IDF (arrondis) pour chaque document :
print("Vecteurs TF-IDF :")
for idx, vec in enumerate(tfidf_vectors):
print(f"Document {idx}: {vec}")
# Afficher la paire de documents les plus similaires et leur distance arrondie
print("\nPaire de documents les plus similaires (indices) :", nearest_pair)
main(text)
# 7. Résultat :
# Vecteurs TF-IDF :
# Document 0: [0.0, 0.0, 0.021, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.1, 0.0, 0.0, 0.1, 0.05, 0.0, 0.0, 0.1, 0.0, 0.05]
# Document 1: [0.0, 0.1, 0.021, 0.0, 0.0, 0.0, 0.0, 0.0, 0.1, 0.0, 0.0, 0.0, 0.0, 0.05, 0.0, 0.0, 0.0, 0.1, 0.05]
# Document 2: [0.134, 0.0, 0.0, 0.067, 0.134, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.134, 0.0, 0.0, 0.067, 0.067, 0.0, 0.0, 0.0]
# Document 3: [0.0, 0.0, 0.025, 0.0, 0.0, 0.12, 0.12, 0.12, 0.0, 0.0, 0.12, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
# Paire de documents les plus similaires (indices) : (0, 1)
Commentaires :
- le résultat correspond bien à la comparaison intuitive des phrases 1 et 2 (indices 0 et 1) ;
- les vecteurs de chaque document sont bien composés des fréquences relatives des 19 mots différents composant le corpus.
Concernant unravel_index() du point 6 :
• explication intuitive
• numpy.org/unravel_index
Nous avons ainsi représenté en chiffres, sous la forme de vecteurs, des notions telles que la valeurs des composants du prix d'une maison, et le nombre des mots caractéristiques d'une phrase (ce qui permet d'approcher sa signification, ... laquelle peut encore être affinée en vectorisant les mots eux-mêmes : cf. Word2vec).
Optimisation de modèle
Quoi
Un modèle évolue grâce à un entraînement qui lui permet d’être de plus en plus performant. Le principe consiste, en utilisant un jeu de données d’entraînement, à mesurer l’écart entre la réponse fournie par le modèle (variable dépendante calculée) et la réponse attendue (variable dépendant observée), et à ajuster le modèle pour minimiser cet écart (appelé "fonction de perte" ou "fonction de coût").
Les termes "ajustement/optimisation" (du modèle) – qui désignent le processus d'entraînement des modèles par minimisation (ou maximisation) d'une fonction de coût ou de perte – sont généralement remplacés par "apprentissage" (par le modèle) lorsque le processus est automatisé.
Le processus d'apprentissage, par lequel la performance d'un modèle est maximisée, est un processus d'essai-erreur visant à trouver un équilibre optimal entre deux phénomènes d'ajustement :
sur-ajustement ("overfitting") : le modèle a une précision élevée sur l'ensemble d'entraînement, mais celle-ci chute sur l'ensemble de test. Cela indique que le modèle a appris de manière trop spécifique les données d'entraînement, ce qui empêche une bonne généralisation aux données nouvelles.
Par "trop spécifique", on entend que le modèle apprend notamment des détails et les bruits des données d'entraînement. La prise en compte de détails rend le modèle trop complexe.
- Le sur-ajustement concerne également la méthode du plus proche voisin [exemple]. La fonction knn.score calcule la précision de ce type de modèle.
sous-ajustement ("underfitting") : la précision est faible tant sur l'ensemble d'entraînement que sur l'ensemble de test. Cela signifie que le modèle n'a pas appris suffisamment les motifs ou relations présentes dans la distribution réelle des données, ce qui limite sa capacité à faire des prédictions correctes.
| Entraînement | Test | |
|---|---|---|
| Sur-ajustement | Haute précision | Basse précision |
| Sous-ajustement | Basse précision | Basse précision |
Comment
Une bonne précision (petite erreur) sur l’ensemble de test est donc un indicateur d’une bonne capacité de généralisation. Cependant ce n'est pas une garantie absolue : si l’ensemble de test est trop similaire aux données d’entraînement, une faible erreur de test peut simplement indiquer que le modèle reconnaît des motifs déjà vus, sans pour autant bien généraliser à des données réellement nouvelles.
De même, une petite erreur d'entraînement ne garantit pas que le modèle prédit réellement bien les nouvelles données : Un modèle très complexe (par exemple, un réseau de neurones profond avec beaucoup de paramètres) peut surapprendre (overfitting), c'est-à-dire mémoriser les données d’entraînement sans être capable de bien prédire des données réellement nouvelles.
Seuils recommandés pour les tests de précision :
- données d'entraînement : 85-95 % ;
- données de test : 80-90 %.
Au-delà de ces pourcentages, les gains deviennent marginaux et le risque de surajustement important.
- car le modèle est conçu directement sur l'ensemble d'entraînement, il devrait donc généralement fonctionner au moins aussi bien sur ces données ;
- le surajustement entraîne souvent une précision d'entraînement supérieure à la précision de test.
Pour maximiser la performance d'un modèle (c-à-d sa précision et généralisation), on peut améliorer :
les données : les échantillons d'entraînement et de test sont-ils fiables, représentatifs et suffisamment diversifiés ... ?
La séparation des données de l'échantillon entre données d'entraînement et de test est-elle non-biaisée ? Une solution simple consiste à diviser les données en n ensembles différents et à entraîner le modèle n fois, à chaque fois avec une combinaison différente de n - 1 ensembles, l'ensemble restant étant utilisé comme ensemble de test. De cette façon, vous obtiendrez n estimations sur les performances de votre modèle sélectionné lors de l'utilisation de données non vues. C'est ce qu'on appelle la validation croisée avec omission d'un élément, et c'est l'un des moyens les plus simples de réaliser une validation croisée. La fonction python train_test_split permet de diviser un ensemble de données en sous-ensembles d'entraînement et de test.
le modèle : les variables explicatives et les hyper-paramètres (par exemple k dans la méthode des k plus proches voisins) sont-ils pertinents (en termes quantitatifs et qualitatifs).
Une technique utilisée pour empêcher le surajustement (régularisation) dans les modèles d’apprentissage automatique, en particulier les modèles d’apprentissage profond, est l'abandon ("dropout").
Un bon échantillon de test reflète fidèlement la distribution réelle, tout en contenant des exemples suffisamment nouveaux pour évaluer la robustesse et la généralisation du modèle.
Un art
Il n’existe pas de méthode précise permettant de déterminer à l’avance quelle méthode d'optimisation et quelle manière de représenter les données produiront les meilleurs résultats. Certaines méthodes d’apprentissage automatique sont bien meilleures que d’autres pour une tâche particulière. En pratique, l'optimisation de modèle est un art pragmatique qui implique beaucoup d’expérimentation et la meilleure méthode ne peut souvent être trouvée que par essais et erreurs.
Le facteur le plus important pour déterminer si une application réussira n'est souvent pas la méthode d'optimisation choisie, mais la façon dont vous l'utilisez : la quantité et la qualité des données d'entraînement, la façon dont les données sont prétraitées et représentées, la façon dont les résultats sont interprétés et appliqués, etc. Cependant, à un moment donné, les méthodes elles-mêmes peuvent devenir le facteur limitant. L'une de ces limites est la linéarité du modèle [source].
Pour modéliser une courbe en cloche, une solution consiste à prétraiter les données en découpant la fonction en segments considérés comme des relations linéaires (chacune avec coefficient propre), de sorte que la variable continue considérée devient une variable catégorielle ⇔ on obtient une fonction en escalier. Mais trouver la bonne façon de coder les données peut être un travail "manuel" fastidieux : quel est le meilleur découpage ?, davantage de paramètres dans le modèle, risque plus élevé de surajustement (à moins que nous n'ayons suffisamment de données).
Heureusement, il existe une autre voie. Si nous soupçonnons qu'il peut y avoir des propriétés non linéaires dans les données, nous pouvons également appliquer des méthodes non linéaires telles que la méthode du voisin le plus proche ou les réseaux neuronaux. Pour aborder ces notions, il nous faut passer par la régression logistique ...
Régression logistique
La régression linéaire et la méthode du plus proche voisin produisent différents types de prédictions. La régression linéaire donne des sorties numériques, tandis que le plus proche voisin produit des étiquettes à partir d’un ensemble fixe d’alternatives («classes»). Avec la régression logistique, on peut prendre la sortie de la régression linéaire, qui est un chiffre, et on prédit une étiquette A si l’étiquette est supérieure à zéro, et une étiquette B si l’étiquette est inférieure ou égale à zéro. Ainsi, au lieu de prédire simplement une classe ou une autre, la régression logistique peut aussi nous donner une mesure de l’incertitude quant à la prédiction.
Pour analyser mathématiquement la notion de régression logistique, il faut commencer par exposer la fonction logistique.
Fonction
logistique
La régression logistique est la fonction logistique d'une régression linéaire, et constitue le modèle du neurone formel. Mais ne brûlons pas les étapes, et commençons par approfondir la notion de fonction logistique. Celle-ci est non linéaire, car elle ne peut pas être exprimée comme une combinaison linéaire de ses variables (sa forme n'est pas une droite).
La fonction logistique est basée sur la fonction exponentielle. Deux exemples fréquents sont :
- la fonction sigmoïde S(x) = 1 / (1 + exp(-x)) :
- produit une sortie entre 0 et 1 (ce qui permet d’interpréter cette valeur comme une probabilité) ;
- idéale pour les problèmes de classification binaire ;
- convient pour une seule sortie activée.
la fonction sofmax σ(x)j = ezj / ∑k=1K ezk : un vecteur z = ( z1 , … , zK ) est transformé en un vecteur σ(z) de K nombres réels strictement positifs et de somme 1, et tel que la composante j du vecteur σ(z) est égale à l'exponentielle de la composante j du vecteur z divisée par la somme des exponentielles de toutes les composantes de z. Il s'agit donc d'une généralisation de la fonction logistique qui :
- produit une distribution de probabilités (la somme des sorties est égale à 1). ;
- convient aux problèmes de classification multi-classes où l'on doit choisir une seule classe parmi plusieurs ;
- transforme un vecteur d'entrée en probabilités normalisées.
Régression
logistique
La régression logistique, fonction logistique d'une régression linéaire, constitue le modèle du neurone formel.
Avant d'entrer dans le vif du sujet, il est utile de comparer régressions linéaire et logistique afin de bien comprendre ce qu'apporte la transformation d'une combinaison linéaire des variables d'entrée en fonction non linéaire :
- régression linéaire :
- objectif : prédire une valeur continue (par exemple, un prix, une température, etc.) ;
optimisation : minimiser l'erreur quadratique (squared error), c'est-à-dire la différence au carré entre les valeurs prédites et les valeurs observées.
- régression logistique :
- objectif : prédire une probabilité (entre 0 et 1) qu'une observation appartienne à une classe donnée (par exemple, "oui" ou "non") ;
Donnée Var. explic. Probabilité Var. dép. Email 1 Contient "gagner" ? 0.9 1 (spam) Email 2 Contient "offre" ? 0.2 0 (pas spam) optimisation : maximiser la vraisemblance (likelihood) des prédictions par rapport aux réponses observées. Cela se fait en minimisant la fonction de perte logistique (log loss), qui mesure l'écart entre les probabilités prédites et les étiquettes réelles : si l'étiquette observée est de classe 1, la probabilité est directement obtenue à partir de la sortie sigmoïde ; si l'étiquette observée est de classe 0, la probabilité est obtenue à partir de un moins la sortie sigmoïde. La perte logarithmique pour un ensemble de données donné est la somme des logarithmes négatifs de ces probabilités (il existe des fonctions Python spécifiques pour la calculer et minimiser).
- objectif : prédire une probabilité (entre 0 et 1) qu'une observation appartienne à une classe donnée (par exemple, "oui" ou "non") ;
Ainsi la régression logistique est telle que :
- variables dépendantes observées (cible) : étiquettes binaires, souvent codées comme 0 (pour "non") ou 1 (pour "oui"). Par exemple, dans un modèle de prédiction de spam, "1" pourrait représenter "spam" et "0" "non-spam".
- variables dépendantes calculées : la régression logistique ne prédit pas directement une étiquette binaire, mais plutôt une probabilité (comprise entre 0 et 1) que l'observation appartienne à la classe "1" (ou "oui"). Cette probabilité est calculée à l'aide de la fonction logistique (sigmoïde) :
P(Y=1 | X) = 1 + e - (β0 + β1 * x1 + ... + β0 * x1)
où les βi xi sont les coefficients et variables indépendantes. - seuil de décision : Pour convertir cette probabilité en une prédiction binaire, on utilise généralement un seuil (par défaut 0,5). Si la probabilité est ≥ 0,5, on prédit "1" (oui), sinon on prédit "0" (non).
Réseaux de neurones artificiels
2. Réseau multicouche
3. Apprentisage automatique
4. Focus sur l'IA générative (conversationnelle)
5. L'art de la modélisation
Neurone formel
Nous venons de voir que la régression logistique, fonction logistique d'une régression linéaire, constitue le modèle du neurone formel.
Le terme "neurone" dans l'expression "neurone formel" n'est pas qu'une analogie avec le neurone biologique. Il s'agit bien d'une modélisation mathématique et informatique du neurone biologique.
Neurone biologique
Le schéma ci-dessus montre que chaque neurone ne peut être considéré indépendamment du réseau dont il constitue un nœud. Le neurone formel exprime le fait qu'à chaque entrée d'un neurone (cf. dendrites) correspond la sortie d'un neurone "amont" (cf. axone).
Dès 1943, le neurologue Warren McCulloch et le psychologue logicien Walter Pitts, travaillant tous les deux sur l’action des neurones dans le cerveau humain, mettent au point un modèle de "réseau de neurones". L’idée est donc qu’un "neurone" artificiel ou formel pourrait accueillir des entrées provenant de neurones d’une couche précédente. Ce "neurone" ferait alors, tel un automate, la somme des entrées de la couche précédente, une somme qui serait pondérée par des "poids" (ces poids miment la plasticité synaptique des réseaux biologiques). Cette somme serait alors soumise à une fonction d’activation non linéaire qui, agissant comme un seuil franchi ou non, détermine si le neurone active ou non sa sortie – l’application de cette fonction à la somme des valeurs issues des entrées des couches précédentes permettant ou pas d’atteindre une valeur seuil donnée.
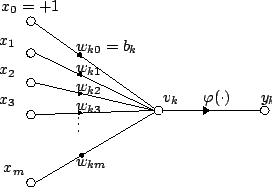
Neurone formel
Chaque neurone correspond donc à une somme pondérée, dont chaque coefficient de pondération relie une sortie de la couche précédente à une entrée de la couche suivante, de sorte que chaque variable de sortie s'exprime mathématiquement par yj = φ *( ∑i=1 n wij * xi + bj ) où :
wij : coefficients de pondération associés à la fonction yj ("poids synaptique", qui définit la force du lien entre deux neurones) ;
b : un biais, qui permet de déplacer la fonction d'activation/transfert et d'ajuster encore plus la sortie du neurone (il permet au neurone de s'activer même lorsque la somme des entrées est nulle) ;
φ() : fonction d'activation de la fonction de transfert yj (le terme "activation" est emprunté directement aux neurosciences où les neurones communiquent en envoyant des impulsions électriques à d’autres neurones lorsqu’ils sont activés par des stimuli reçus).
Par extension, le modèle de régression logistique est également celui du réseau neuronal, mais la mise en réseau des neurones, au travers de couches neuronales, induit un phénomène d'émergence par lequel le tout est plus que la somme de ses composantes.
Réseau multicouche
La régression logistique peut être vue comme un cas particulier d’un réseau de neurones à une seule couche (sans couche cachée), où une combinaison linéaire des entrées est transformée par une fonction sigmoïde ou softmax. Cependant, lorsqu’on empile plusieurs couches neuronales, on observe un phénomène d’émergence : le réseau devient capable d’apprendre des représentations hiérarchiques et abstraites des données. Ce phénomène repose sur le fait que chaque couche intermédiaire transforme et réencode l’information, permettant au réseau d’extraire progressivement des caractéristiques de plus en plus complexes.
Voici un réseau neuronal qui se compose d'une couche d'entrée avec cinq nœuds (les variables explicatives du modèle), d'une première couche cachée avec deux nœuds (le nombre de variables explicative), suivie d'une deuxième couche cachée également avec deux nœuds, et enfin d'une couche de sortie avec un seul nœud. De plus, il existe un seul nœud de biais pour chaque couche cachée et la couche de sortie (PS : le but du nœud de biais est fonctionnellement le même qu'avec le terme d'interception dans une régression linéaire : il peut décaler l'entrée provenant d'une couche vers une autre couche d'une valeur constante).
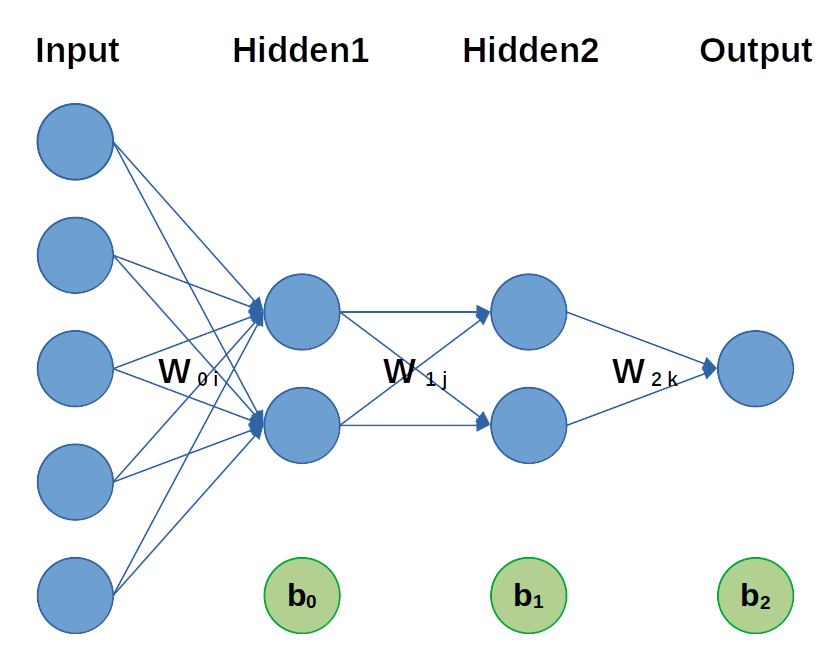
Chaque neurone de la première couche intermédiaire est une combinaison linéaire des neurones de la couche d'entrée (c-à-d des valeurs mesurées des variables explicatives). L'activation de ces combinaisons linéaire par la transformation non linéaire de la couche, constitue la sortie de cette première couche intermédiaire ... et l'entrée de la suivante, et ainsi de suite jusqu'à la couche de sortie, composée de la valeur calculée des variables dépendantes.
Ainsi dans le schéma ci-dessus :la couche d'entrée comprend cinq neurones : ce sont les valeurs des variables explicatives, transformées en données numériques pour qu’elles puissent être traitées par le réseau ;
2 couches de 2 neurones intermédiaires, chacune constituant un type de fonction de seuil (N.B. : les couches intermédiaires peuvent être composées de nombres différents de neurones).
une couche de un ou plusieurs neurones de sortie : génère les prédictions finales (probabilités), et transforme les valeurs obtenues en réponse au problème posé (par exemple, si l’on souhaite savoir s’il s’agit d’un chat ou un chien sur une image, la couche de sortie donne la réponse grâce à un neurone correspondant à la probabilité qu’il y ait un chien sur une image numérisée en entrée, et un autre neurone correspondant à la probabilité qu’il y ait un chat sur l’image) ;
Par "réseau profond" on entend que le nombre de couches intermédiaires est élevé.
Le script Python ci-dessous montre une application correspondant au réseau ci-dessus, où la fonction d'activation pour les nœuds cachés est ReLU (qui est non linéaire) et la fonction d'activation pour le nœud de sortie est la fonction identité (qui est linéaire). La fonction d'activation ReLU renvoie soit la valeur d'entrée de la fonction, soit zéro, selon la valeur la plus élevée, et l'activation linéaire renvoie simplement l'entrée en sortie. Le réseau de neurone produit une estimation pour une maison décrite par le vecteur de caractéristiques [82, 2, 65, 3, 516].
import numpy as np
w0 = np.array([[ 1.19627687e+01, 2.60163283e-01],
[ 4.48832507e-01, 4.00666119e-01],
[-2.75768443e-01, 3.43724167e-01],
[ 2.29138536e+01, 3.91783025e-01],
[-1.22397711e-02, -1.03029800e+00]])
w1 = np.array([[11.5631751 , 11.87043684],
[-0.85735419, 0.27114237]])
w2 = np.array([[11.04122165],
[10.44637262]])
b0 = np.array([-4.21310294, -0.52664488])
b1 = np.array([-4.84067881, -4.53335139])
b2 = np.array([-7.52942418])
x = np.array([[111, 13, 12, 1, 161],
[125, 13, 66, 1, 468],
[46, 6, 127, 2, 961],
[80, 9, 80, 2, 816],
[33, 10, 18, 2, 297],
[85, 9, 111, 3, 601],
[24, 10, 105, 2, 1072],
[31, 4, 66, 1, 417],
[56, 3, 60, 1, 36],
[49, 3, 147, 2, 179]])
y = np.array([335800., 379100., 118950., 247200., 107950., 266550., 75850.,
93300., 170650., 149000.])
def hidden_activation(z):
# ReLU activation
return np.maximum(0, z)
def output_activation(z):
# identity (linear) activation
return z
x_test = [[82, 2, 65, 3, 516]]
for item in x_test:
h1_in = np.dot(item, w0) + b0 # this calculates the linear combination of inputs and weights
h1_out = hidden_activation(h1_in) # apply activation function
# Second hidden layer
h2_in = np.dot(h1_out, w1) + b1
h2_out = hidden_activation(h2_in)
# Output layer
output_in = np.dot(h2_out, w2) + b2
output_out = output_activation(output_in)
print(output_out)
# Résultat
# [257136.43628059]
On constate que le résultat est proche du prix des maison 4 et 6, dont les attributs sont effectivement proches.
La magie se produit au point où les neurones à l'intérieur du réseau utilisent des fonctions d'activation non linéaires. Si nous utilisons des activations non linéaires telles que les fonctions sigmoïde ou ReLu, le modèle devient soudainement beaucoup plus puissant que les modèles linéaires. En fait, il devient si puissant qu'avec suffisamment de nœuds dans le réseau, nous pouvons apprendre à ajuster parfaitement pratiquement n'importe quelle donnée. Une façon technique d'exprimer cela est de dire que les réseaux neuronaux sont des « approximateurs de fonctions universelles ».
La puissance des réseaux neuronaux a un prix. Les problèmes plus complexes nécessitent des réseaux plus grands, les réseaux plus grands contiennent plus de paramètres et plus de paramètres nécessitent plus de données. Si nous essayons d'adapter un grand réseau avec trop peu de données, le modèle sera sur-adapté et fera de moins bonnes prédictions qu'un réseau plus simple : même un modèle de régression logistique simple peut facilement battre un grand réseau neuronal s'il n'y a que peu de données. La raison pour laquelle l'optimisation des paramètres d'un réseau neuronal pour s'adapter aux données d'entraînement est si difficile est que les fonctions d'activation ne sont pas linéaires, le « paysage » d'optimisation est également très irrégulier et présente de nombreux optima locaux où l'optimiseur peut se retrouver bloqué [source].
Fonction
d'activation
Une fonction d'activation φ gère un seuil θj (c-à-d de la non-linéarité). À chaque couche intermédiaire correspond donc un type de seuil, et ses noeuds correspondent à des valeurs possibles pour ce type de non linéarité, chacune de ces valeurs étant déterminée par ses propres poids et biais (N.B. : c'est ce qui permet à chaque neurone de prendre des décisions individuelles et de contribuer à des sorties différentes même au sein de la même couche). Des types de seuil fréquents sont les fonctions non linéaires sigmoïde et ReLU.
Un exemple de problème non linéaire est la disjonction exclusive ou fonction "ou exclusif" (appelée aussi XOR, connue en électricité sous la forme du montage va-et-vient et utilisée en cryptographie.
Apprentissage automatique
L'apprentissage est automatique lorsque le processus de conception de l'algorithme est intégré dans celui-ci.
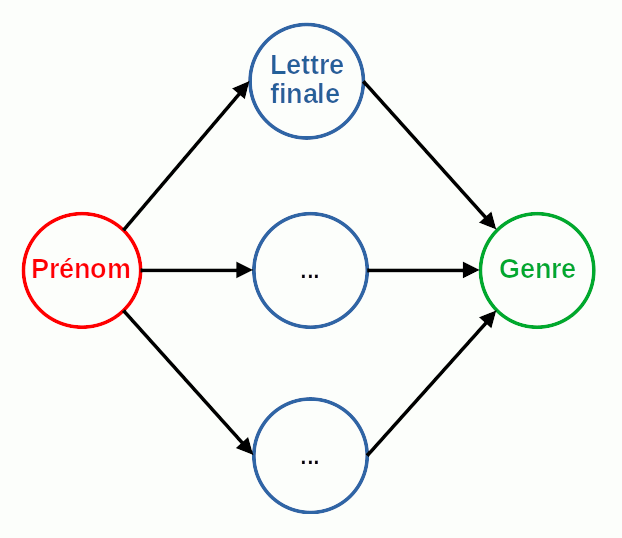
L'apprentissage consiste notamment à déterminer la valeur des coefficients de pondération. Ainsi, pour déterminer si un prénom est masculin ou féminin, l'IA devra identifier une série de propriétés discriminantes. Par exemple, s'il s'avère que 80 % des prénoms qui se terminent par la lettre "e" sont féminins, alors un des neurones de la couche intermédiaire pourrait traiter l'identification de la dernière lettre du prénom.
Un autre exemple est celui d’une population dont on connaît la taille et le poids et dont on souhaite classer les individus par genre. Les caractéristiques de la population sont deux variables continues "taille" et "poids" et les deux classes auxquelles les individus peuvent appartenir sont "homme" ou "femme". On peut représenter les individus par des points situés sur un graphique en deux dimensions qui aurait pour abscisse la taille des individus et pour ordonnée leur poids. Les hommes étant généralement plus grands et massifs que les femmes, le graphique fait apparaître deux groupes de points qui représentent respectivement les hommes et les femmes et sont à peu près séparés l’un de l’autre. L’apprentissage va consister à déterminer la droite qui sépare "le mieux possible" le groupe des points représentant les hommes et celui des points représentant les femmes, pour le jeu de données d’apprentissage choisi (c’est-à-dire un ensemble d’individus dont on connaît la taille et le poids, et dont chacun dispose de son étiquette "homme" ou "femme"). Dès lors on pourra déterminer la classe probable d’un nouvel individu (en l’occurrence son genre) en connaissant son poids et sa taille, selon que le point qui le représente sur le graphique sera placé d’un côté ou de l’autre de la droite séparatrice [source].
Les méthodes d'apprentissage sont spécifiques à des tâches. Deux méthodes simples sont :
la classification : pour la "prédiction" d'une variable qualitative (exemple : la reconnaissance d'images). La capacité de classer des éléments en deux groupes, ce qui implique de pouvoir traiter algorithmiquement la notion de "proche de", en termes spatial ou sémantique. À partir de cet apprentissage, un algorithme pourra alors prédire le comportement d'un individu, avec une probabilité assez élevée, après avoir identifié le groupe dont il est comportementalement le plus proche.
la régression : pour la "prédiction" d'une variable quantitative (exemples : prix de vente de biens immobiliers en fonction de leur emplacement, de leur taille et de leur état ; ...). L’idée de base, en régression linéaire, consiste à additionner les effets de chacune des variables des caractéristiques afin de produire la valeur prédite. Le terme technique pour ce processus d’addition est «combinaison linéaire». Par exemple, lorsqu’on utilise la régression linéaire pour prédire l’espérance de vie, la pondération du tabac (le nombre de cigarettes fumées chaque jour) correspond à une diminution de 6 mois, ce qui signifie qu’une cigarette de plus par jour raccourcit en moyenne votre espérance de vie d’une demi-année.
Dès les années 1950, des algorithmes d’apprentissage permettant de faire varier la force de connexion entre les neurones artificiels ont été théorisées sous le nom de "perceptron". Avec les perceptrons, le poids synaptique au sein des neurones formels va se trouver modifié et amélioré selon des processus d’apprentissage. Le perceptron monocouche permet d'automatiser le classement binaire linéaire supervisé d’une population, c-à-d un processus permettant de séparer une population en deux classes, en connaissant déjà la classe d’une partie des individus. Dans ce type de problème de classification linéaire, le classifieur permet de séparer deux classes d’une population par une droite ou un plan, que l’on qualifie spécifiquement d’hyperplan dans le cadre des réseaux de neurones. Ce réseau est ainsi capable d’apprentissage.
Les poids sont ajustés à chaque itération de l'entraînement via un processus d'optimisation comme la rétropropagation (backpropagation). À chaque passage des données dans le réseau, les poids sont modifiés afin de minimiser l'erreur entre la prédiction du réseau et la valeur réelle (la sortie désirée).
Convolution
Lorsqu'un objet en entrée a beaucoup de variables explicatives (ex. pixels d’une image), une couche de convolution permet de réduire la complexité en extrayant des motifs locaux (bords, textures, formes). La méthode consiste à appliquer une petite matrice de poids (un filtre) à des zones ("patchs") de l’image (un paramètre par pixel de la zone) pour produire des cartes de caractéristiques ("feature maps"). Un même filtre peut être utilisé sur différentes régions, afin de détecter des motifs identiques indépendamment de leur position (par exemple les deux oreilles d'un chat). Les couches successives de convolution extraient des caractéristiques de plus en plus abstraites (ex. d’abord des bords, puis des textures, puis des formes complexes).
Rétropropagation
Bien que les réseaux à plusieurs couches soient capables de traiter des situations de classification non linéaire, avec plusieurs neurones au lieu d’un seul, il est difficile d'entraîner le modèle car chaque neurone influence le résultat final différemment. Comment alors savoir quel poids synaptique ou quel biais modifier et de quelle façon pour atteindre le résultat optimal voulu ? Une solution consiste à utiliser une technique issue de la résolution des problèmes de fonctions convexes en mathématiques appelée la "descente de gradient ". L’algorithme dit de "rétropropagation du gradient" permet de trouver un minimum global, c’est-à-dire le point où le modèle obtient les meilleurs résultats. L'ajustement commence par les neurones de la couche de sortie, puis remonte couche par couche jusqu'à l’entrée. Chaque poids et biais de chaque neurone reçoit une correction qui fait intervenir la dérivée partielle correspondante de la fonction de perte et un taux d’apprentissage [source].
Le plus grand avantage de la rétropropagation est qu'elle permet par exemple aux modèles de texte de "se souvenir" de ce qui a été dit précédemment. Par exemple, si le texte commence par « Isabelle a un nouveau chiot. Elle m'a montré une photo de lui aujourd'hui », le modèle peut lier le mot "Elle" à "Isabelle" et le mot "ça""à "nouveau chiot", même si l'ensemble du texte n'est pas traité comme une séquence d'entrée. Cela est utile pour la traduction automatique et la génération de texte. Si le texte continuait par « Il est vraiment ... », une suite probable serait "adorable" ou "trop mignon" (selon que le réseau est formé sur un article du journal Le Monde, ou sur un réseau social), tandis que la même suite serait assez peu probable si au lieu du mot "chiot", nous avions eu le mot "tronçonneuse" ou "Harley Davidson" [source].
Un phénomène biologique similaire à la rétropropagation du gradient a été observé dans les réseaux de neurones des mammifères. La rétropropagation neuronale désigne la propagation d’un potentiel d’action dans un neurone, non pas vers la terminaison de l’axone (propagation normale), mais au rebours, en direction des dendrites, d’où provenait la dépolarisation originelle [source].
Transformeurs
Les réseaux à rétropropagation sont plus complexes et généralement encore plus difficiles à entraîner. Une alternative à la rétropropagation est l'architecture de transformeur, qui permet également la capacité d'identifier les dépendances à longue portée entre les mots. La technique est basée sur des mécanismes dits d'attention qui identifient les mots les plus pertinents à utiliser pour prédire la suite probable d'un texte.
Le transformeur traite tous les éléments de la séquence en parallèle (contrairement à la rétropropagation, qui est séquentielle), ce qui facilite l'entraînement mais au prix de grandes quantités de données d'entraînement et d'un coût computationnel élevé pour les longues séquences.
Ainsi dans la phrase « Elle a acheté un livre parce qu’elle adore lire », le modèle calcule un score d’attention entre "elle" (première occurrence) et "lire", puis le mécanisme d’attention renforce le lien entre ces mots, même s’ils sont éloignés.
Apprentissage
non supervisé
Dans l'apprentissagse supervisé, les réponses correctes sont disponibles (étiquetage) et la tâche de l’algorithme d’apprentissage automatique consiste à trouver un modèle qui les prédit sur la base des données d’entrée, ou à en reproduire des variantes artificielles (exemple : visages artificiels).
Ce qu'il faut entendre par "apprentissage automatique", c'est l'apprentissage non supervisé. Dans ce cas, les réponses correctes ne sont pas fournies. Cela change totalement la donne, étant donné qu’on ne peut pas élaborer le modèle en l’adaptant aux réponses correctes des données d’entraînement. Cela rend aussi l’évaluation des performances plus compliquée, car on ne peut pas vérifier si le modèle acquis fonctionne bien ou non. Les méthodes d’apprentissage non supervisé typiques tentent d’apprendre une forme de «structure» qui sous-tend les données. Cela peut signifier, par exemple, que des éléments similaires sont placés à proximité les uns des autres tandis que les éléments différents sont éloignés les uns des autres.
Donnés synthétiques. En plus des données préexistantes, issues du monde réel et du monde virtuel qu’est Internet, les modèles d’IA générative ont de plus en plus recours à des données créées artificiellement dont les propriétés statistiques prédictives sont proches des données réelles mais dont les conditions de mise à disposition sont moins chères, plus accessibles ou ne contiennent pas d’informations personnelles ou sensibles. En tant que données de nature secondaire, dérivées de corpus qui peuvent eux-mêmes contenir des biais, les données synthétiques posent à la fois la question des biais liés aux données en général mais elles peuvent aussi apporter leurs propres biais en plus (biais de représentation, biais de distribution, biais de modèle ou encore biais d’utilisation), et induire des erreurs dans les modèles d’IA, si elles ne reflètent pas correctement la réalité ou si elles sont mal calibrées. Elles peuvent aussi renforcer des biais existants et déformer les résultats produits ensuite par les modèles d’IA. Enfin, elles peuvent enfermer les modèles dans une boucle autodestructrice, appelée en anglais autophagous ou self-consuming loop, dégradant progressivement la qualité et/ou la diversité des données synthétiques et menant à un échec du modèle [source].
Outre les données synthétiques, les modèles disposent d’un autre moyen de généralisation sans recourir à des données réelles : il s’agit d’un mode d’apprentissage où le modèle est entraîné à reconnaître et à catégoriser des objets ou des concepts sans avoir vu d’exemples de ces catégories ou concepts au préalable. On parle à ce sujet de Zero-Shot Learning (ZSL). Par exemple un modèle d’intelligence artificielle qui n’a jamais été entraîné à reconnaître un zèbre peut toutefois le reconnaître car il a été formé à reconnaître un cheval. Ainsi les modèles pré-entraînés sur de grands corpus peuvent être optimisés pour réaliser une nouvelle application, en utilisant peu de données supplémentaires spécifiques à cette tâche.
Des logiciels d'apprentissage pour IA sont PyTorch (Meta) et TenserFlow (Google) et fast.ai.
Les réseaux de neurones peuvent conduire à toutes sortes d'applications : classification, recommandation, prédiction, vision, génération de contenus. La génération de contenus textuels a donné l'IA conversationnelle.
Focus sur l'IA conversationnelle
Quoi
L'IA conversationnelle constitue la partie émergée de "l'iceberg IA", en offrant le moyen le plus intuitif d'interagir avec l'IA. Elle repose sur des méthodes statistiques, appelées modèles de langage, visant fondamentalement à prédire le mot suivant dans une séquence de mots.
L'agent conversationnel est capable de discuter avec l'utilisateur sur n'importe quel sujet, et en produisant des phrases dont la syntaxe fait sens. La performance est véritablement bluffante. Cependant il importe d'interpréter toujours avec un sens critique les affirmations produites par les agents conversationnels, car ils peuvent produire des affirmations fausses et des raisonnements "logiques" erronés. La raison en est que l'agent conversationnel ne fait rien d'autre que "d'inventer" des réponses statistiquement probables en termes de cohérence syntaxique, et de proposer la plus probable.
Exemple. Le 12 décembre 2024 il a été constaté qu'au problème simple "Alice a 4 sœurs et 1 frère. Combien de sœurs a le frère d’Alice ?", ChatGPT4o a donné une réponse fausse [constater]. Notez que si à la question "Quelle est la capitale de la France ?" il vous répond "Paris", et que vous répondez "C'est faux", alors il persistera dans sa réponse, car la probabilité de vraisemblance que son modèle a calculé est très probablement quasiment égale à 100 %, étant donné la trivialité de la question.
Enfin, dans ses réponses, un modèle de langage peut faire appel à des modèles correspondant à d'autres type d'IA, par exemple pour la reconnaissance d'image. Ainsi lorsque je réalise un schéma pour représenter des notions complexes (par exemple le schéma supra "Interprétation vs compilation") je peux en télécharger le fichier image dans une conversation, et demander à l'IA conversationnelle de la commenter. L'agent conversationnel est capable d'en interpréter le contenu grâce à son modèle de reconnaissance d'image.
Supervisé
et "aligné"
Les modèles conversationnels sont pourvus d'une fonction d'apprentissage, fonctionnant sur base d'une banque de données collectées sur Internet (sites officiels, Wikipedia, ...). Ils ne sont pas pour autant laissés à eux-mêmes : des fonctions et paramètres sont déterminés par leurs développeurs, afin de minimiser la production de résultats aberrants ou politiquement incorrects (notions d'apprentissage supervisé et filtrage).
La supervision ne concerne pas que des données objectives, mais également des données subjectives, de sorte que la supervision comprend une part de normalisation (wokisme), pudiquement qualifiée "d’alignement", par filtrage des données d'entrée comme de sortie du modèle. Il est attendu du modèle qu’il soit le plus possible en phase avec les attentes ou les préférences d’un utilisateur humain et pour cela le modèle d’IA va apprendre les réponses les plus souhaitables à partir de retours sur ses actions (dans une logique de récompense : du type "bonne réponse" ou "mauvaise réponse"). En pratique, il peut s’agir d’un alignement sur les normes éthiques et socialement acceptables, de la recherche de discours politiquement correct par rapport à des valeurs morales perçues comme convenables, ou encore d’un bannissement de certains propos offensants, tels que l’emploi de termes racistes ou sexistes, etc., en pénalisant les retours du modèle qui contiendraient de tels propos. Une variante sans annotation humaine est possible, avec une IA spécifiquement programmée selon des principes moraux et l’on parle alors d’apprentissage par renforcement avec retour de l’IA (Reinforcement Learning with AI Feedback ou RLAIF) » [source].
Le prix de l'apprentissage supervisé
Lors du réglage fin (phase d’alignement en particulier) du LLM ChatGPT, OpenAI a notamment sous-traité cet entraînement à l’entreprise Sama, établie à San Francisco, qui a utilisé des salariés kényans gagnant moins de 2 dollars de l’heure (à partir de 1,46 dollar) pour détecter et étiqueter les contenus toxiques en vue d’éviter que le système ne produise ensuite de tels contenus préjudiciables, comme des propos sexistes, racistes ou violents. Cette information a été rendue publique en 2023 par le magazine Time, dont l’article soulignait que les travailleurs kényans, outre le fait d’être très mal payés, ont été exposés à des contenus traumatisants (pédophilie, nécrophilie, violences extrêmes, viols et abus sexuels, etc.). Un salarié a même décrit son travail comme relevant de la torture et un autre, relayé par un article du Guardian du 2 août 2023, explique avoir été complètement détruit à la suite de cette expérience, quatre des 51 salariés kényans ont même demandé à leur gouvernement d’enquêter sur les conditions de leur « exploitation » et sur le contrat liant Sama à OpenAI1. Cette dernière a refusé de commenter ces révélations tandis que Sama a assuré la mise à disposition 24 heures sur 24 et 7 jours sur 7 de thérapeutes pour ses modérateurs et le remboursement des frais de psychiatres.
Le sens
des mots
Dans l'apprentissage du langage par l'IA, la grammaire ne joue pas un rôle central, elle n'est qu'une propriété émergente : le réseau neuronal ne fait que repérer des régularités, ce qui est exactement comment opère l'apprentissage naturel du langage par les humains, c-à-d par immersion plutôt que par l'étude de la grammaire et du vocabulaire. De même les démonstrations mathématique se font sans logique, mais uniquement via les probabilités conditionnelles.
Les modèles de langage ne déduisent pas mais induisent le sens des mots, via la technique de vectorisation, qui consiste en trois phases principales :
une fois que le jeu de données d’apprentissage a été constitué (ici, un ensemble étendu de textes), les mots sont découpés en unités ou "tokens" qui sont des briques élémentaires de vocabulaire servant d’unités de base pour le modèle : Alice| am|ène| sa| voiture| rouge| au| garage| car| elle| est| en| pan|ne|. ;
ensuite les tokens sont transformés en vecteurs représentant les coordonnées du mot dans un espace possédant un grand nombre de dimensions ;
on peut alors calculer des liens grammaticaux, sémantiques et pragmatiques entre les différents mots d’une séquence.
Cette technique permet une meilleure capacité du modèle en termes de généralisation, en particulier par rapport à des mots rares ou à des variantes linguistiques.
L’hypothèse distributionnelle et les modèles vectoriels de représentation des tokens permettent de calculer une distance entre ceux-ci. Quand cette distance est petite, la proximité des vecteurs dans l’espace vectoriel correspond à une certaine parenté. Les vecteurs des tokens se retrouvant dans des contextes similaires dans le corpus d’apprentissage ont tendance à devenir proches les uns des autres. De plus, un transformer met en œuvre un mécanisme de calcul appelé « mécanisme d’attention », qui permet d’ajuster le poids de chaque token en fonction de tous les autres. Un transformer apprend ainsi les régularités (relations) les plus saillantes entre les tokens, sans être influencé par l’ordre de ceux-ci.
L’architecture Transformer, via son mécanisme « d’attention », sélectionne des informations sur les mots en fonction du contexte de la phrase, y compris pour une proposition dont le sens ne se déduit pas de sa seule formulation. Par exemple, la phrase « Alice amène sa voiture rouge au garage car elle est en panne », pour être correctement comprise requiert de pouvoir (i) déterminer que le pronom "elle" renvoie au sujet et non à l'objet de la phrase ; (ii) lier l'adjectif "rouge" au nom de l'objet.
Si l’on remplace chaque coordonnée des vecteurs par des couleurs, par exemple un dégradé allant du bleu au rouge avec la valeur zéro pour le blanc, on peut représenter visuellement les vecteurs des mots « plongés » (mots qui sont les objets du plongement lexical). Cela permet d’observer des propriétés intéressantes en ne regardant que les coordonnées des vecteurs plongés. Dans l’image qui suit, on constate que les mots « homme » et « femme » ont plus de similitudes entre eux, que chacun d’eux peut en avoir avec le mot « roi », ce qui est normal puisque les deux désignent un genre, alors que « roi » désigne une fonction.
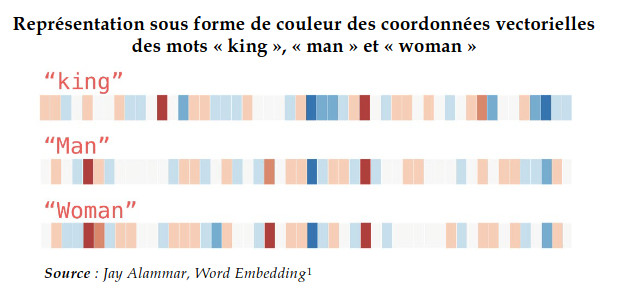
Aussi, si le plongement lexical ("word embedding") est correctement réalisé, il est possible d’effectuer des opérations sur la base du « sens » des mots, entendu comme l’ensemble des relations de proximité ou d’éloignement entre mots que l’apprentissage a permis d’identifier. Par exemple, dans cet espace, le vecteur de différences entre les mots « homme » et « roi » est similaire au vecteur de différences entre les mots « femme » et « reine ». Ainsi, on peut établir l’identité approximative telle que : king→ - man→ + woman→ ≈ queen→
On peut ainsi formaliser mathématiquement des analogies entre les mots, comme par exemple « a est à b ce que x est à y », permettant à des modèles d’affirmer que a et x peuvent être transformés de la même manière pour obtenir b et y, et vice-versa. D’un point de vue formel, ces analogies linéaires entre les mots correspondent à des relations vectorielles où les vecteurs forment dans l’espace vectoriel une structure géométrique de type parallélogramme. Ces quadrilatères ont des propriétés utiles qui peuvent être exploitées. Une analogie linéaire dans l’espace vectoriel entre tel ensemble de mots (ou de tokens) et tel autre ensemble de mots (ou de tokens) montre que leurs vecteurs sont coplanaires et que toute combinaison de ces vecteurs peut être utilisée pour réécrire les structures de relations entre ces éléments en termes statistiques (tester).
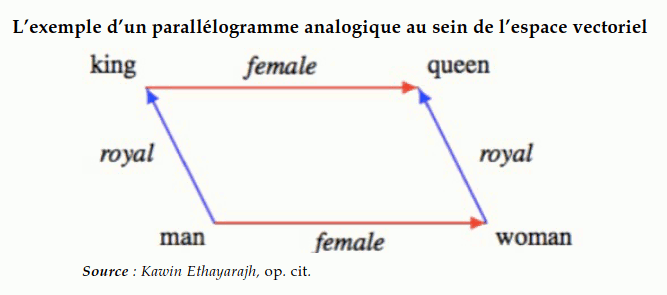
La corrélation entre les mots dans un corpus d’apprentissage est ainsi d’autant plus élevée que la distance euclidienne entre leurs vecteurs est faible. Il est donc possible de réaliser des produits scalaires entre deux vecteurs au sein d’un espace vectoriel et de comparer les produits scalaires de ces vecteurs pour voir lesquels « vont dans la même direction », témoignant de leurs proximités sémantiques.
Ainsi l’IA connexionniste, avec ses méthodes statistiques qui se rapprochent de la logique inductive, peut donner l’impression de se rapprocher davantage de ce que nous appelons communément "compréhension".
Remarques :
les transformers s’appuient sur l’hypothèse distributionnelle selon laquelle des mots qui se trouvent dans des contextes d’apparition similaires tendent à avoir des sens similaires ;
un paramètre clé est celui de la « température » qui exprime le degré d’aléa dans le choix des tokens. À une température élevée, le modèle est plus « créatif » car il peut générer des sorties plus diversifiées, tandis qu’à une température basse, le modèle tend à choisir les sorties les plus probables, ce qui rend le texte généré plus prévisible.
Liste
La liste suivante (non exhaustive) illustre la domination des IA conversationnelles "made in US" et des licences propriétaires. Soulignons à cet égard l'avantage de Mistral pour de petites organisations : licence la plus libre, tourne sur un ordinateur à 800 euros [source].
| Application | Licence | Pays |
|---|---|---|
| chatgpt.com | Propriétaire | USA |
| claude.ai | Propriétaire | USA |
| deepseek.com | Open source | Chine |
| gemini.google.com | Propriétaire | USA |
| meta.ai | Meta Llama 3 Community License | USA |
| mistral.ai | Apache 2.0. | France |
| perplexity.ai | Propriétaire | USA |
Source : comparia.gouv.fr
Bilan énergétique de l'IA
Lorsqu'il s'agit de reproduire des capacités cognitives humaines, l'intelligence artificielle consomme énormément plus d'énergie que le cerveau humain. Avec une consommation énergétique journalière équivalant à deux bananes, l'efficacité énergétique du cerveau humain est époustouflante [source].
Rien d'étonnant à cela. L'intelligence naturelle, étant le résultat d'un processus évolutif de plusieurs millions d'années [source], est nécessairement d'une efficacité redoutable. Par conséquent, en vertu du premier principe de la thermodynamique (rien ne se créé, rien ne se perd), la propension des ordinateurs à surpasser les capacités cognitives des humains ne peut "venir de nulle part", et doit nécessairement impliquer une consommation plus élevée d'énergie.
Un processeur, c’est comme une résistance : presque toute l’électricité qu’il consomme est dissipée en chaleur. C’est pourquoi, en plus de consommer de l’énergie pour faire tourner ses serveurs, un data center doit être climatisé afin de préserver l’intégrité des circuits électroniques.
La seconde couche du schéma ci-dessous (infrastructure) se subdivise en (1) la collecte et le nettoyage de données ; (2) le stockage de données dans de vastes data centers ; (3) l’informatique en nuage (cloud) pour les calculs ; (4) lors de la phase de développement des modèles, le recours spécifique à des supercalculateurs. Les coûts sont immenses, croissants et ont des impacts environnementaux considérables [source].
Schéma simplifié de la chaîne de valeur de l’IA connexionniste

Coûts cachés
du numérique
D'après une étude réalisée par Digital Power Group publiée en 2013 [source] les coûts énergétiques du numérique sont largement cachés, la partie connue n’étant que la pointe de l’iceberg. L’économie numérique de la planète consomme déjà 50% d’énergie de plus que l’aviation du monde entier. Les datacenters ne représenteraient que 20% de l’électricité consommée par les appareils et réseaux numériques, les 80% restants étant très dispersés. Selon DPG la demande d’usage des centres de données augmentera plus vite que leurs gains en efficacité énergétique. Ces tendances vont rendre nécessaire l’usage de plus de charbon, estime l’étude, qui est sponsorisée par deux organisations du secteur minier US [source].
Si l’on considère la totalité de son cycle de vie, le simple envoi d’un mail d’1 mégaoctet (1 Mo) équivaut à l’utilisation d’une ampoule de 60 watts pendant 25 minutes, soit l’équivalent de 20 grammes de CO2 émis. On ne s'étonnera donc pas de constater que le secteur des nouvelles technologies représente à lui seul entre 6 et 10 % de la consommation mondiale d’électricité, soit près de 4 % de nos émissions de gaz à effet de serre. Environ 30 % de cette consommation électrique est imputable aux équipements terminaux (ordinateurs, téléphones, objets connectés), 30 % aux data centers qui hébergent nos données, et 40 % aux réseaux, les fameuses "autoroutes de l‘information" [source].
Selon certaines estimations, à la fin des année 2020 la consommation d’énergie des appareils informatiques consommera 60 % de la quantité totale d’énergie produite, et deviendra totalement insoutenable d’ici 2040. Une solution consiste peut-être à remplacer les actuels processeurs électroniques (qui utilisent des électrons) par des processeurs optiques (qui utilisent des photons, lesquels ne génèrent pas de chaleur et se propagent plus rapidement) [source].
Enfin la consommation énergétique des nouvelles technologies n’est qu’un aspect du défi environnemental qu’elles posent. Ainsi nos smartphones contiennent des dizaine de différents métaux et terres rares (or, cuivre, nickel, zinc, étain, mais aussi arsenic, gallium, germanium, thallium, tantale, indium, ...) qui sont extraits du sous-sol en utilisant des techniques particulièrement destructives et des produits nocifs pour l’environnement comme l’acide sulfurique, le mercure et le cyanure [source].
Effet rebond. Il est cependant à craindre que la réduction de consommation énergétique de l'IA suite au progrès technologique (IA frugale) ne constituera pas une voie de résolution de la problématique énergétique de l'IA, en raison de l'effet rebond (ou paradoxe de Jevons).
Cependant, selon Laurent Bloch, « les analyses de la question sous-estiment souvent les externalités positives de l'informatisation, comme les économies de papier et de transport promises par les communications électroniques ou les économies de transport et de temps permises par le travail à distance et les visio-conférences, même si les transformations sociales induites par ces nouvelles façons de vivre et de travailler sont trop récentes pour que l'on puisse en mesurer précisément les conséquences. Le contrôle informatique des moteurs à combustion interne en a considérablement réduit la consommation de carburant. Bref des économies de tous ordres sont vraisemblablement engendrées par la substitution d'opérations abstraites et symboliques à des actions cinétiques de l'ancienne industrie, mais la quantifications précise de ces effets reste largement à faire » [source].
Risques
2. Normalisation
3. Boîte noire
4. Risque existentiel
Hallucinations
Les IA génératives ont une tendance intrinsèque à « halluciner », c’est-à-dire à générer des propos dénués de sens ou des réponses objectivement fausses sans émettre le moindre doute. Elles produisent des résultats vraisemblables mais pas nécessairement vrai. Ainsi un professeur de droit a ainsi découvert que ChatGPT avait inventé un cas de harcèlement sexuel et fait de lui l’une des personnes accusées ! [source].
« Il existe en fait une latitude donnée aux modèles en termes de créativité de leurs prédictions, qui porte le nom de "température". Les modèles à basse température sont plutôt factuellement fidèles aux informations issues des données d’entraînement tandis que les modèles à haute température introduisent plus d’aléatoire, avec la sélection de tokens statistiquement probablement les moins liés. Ces derniers modèles sont donc plus créatifs et parfois trop, ce qui peut être pertinent pour trouver des idées originales ou écrire de la poésie. Cette créativité peut évidemment être indésirable dans de nombreux autres cas où les outputs insensés ou faux doivent être le plus souvent possible évités. (...) Outre ces hallucinations et erreurs factuelles, les IA connexionnistes sont, en dépit de leur puissance, affectées d’une incapacité à se représenter le monde ou à faire preuve de logique (de sorte) qu’il est facile de piéger ces IA génératives » [source].
Ainsi le 12 décembre 2024 il a été constaté qu'au problème simple "Alice a 4 sœurs et 1 frère. Combien de sœurs a le frère d’Alice ?", ChatGPT-4o a donné une réponse fausse : « Le frère d'Alice a 4 sœurs. Explication : Alice a 4 sœurs et 1 frère. Cela signifie que toutes les personnes mentionnées, y compris le frère, partagent les mêmes sœurs. Ainsi, le frère d'Alice a également les 4 mêmes sœurs ». Dans ce test, ChatGPT-4o a même éprouvé de grandes difficultés à profiter de l'aide qu'on lui donnait : constater]. Les IA connexionnistes ne "raisonnent" pas au sens où nous l’entendons, elles ne font que des prédictions statistiques. Contrairement aux modèles symboliques, elles n’ont pas accès à une base de données de connaissance déterminées, mais s’appuient sur une construction statistique destinée à prédire une suite de mots probable ou plausible. « En plus de cela, les données disponibles pour un LLM donné sont arrêtées dans le temps au moment de leur entraînement, elles ne peuvent pas être facilement actualisées une fois leur entraînement terminé, à moins de relancer un nouvel entraînement et de produire une nouvelle version du modèle, ce qui s’avère complexe et coûteux pour de grands modèles déjà diffusés sur le marché. (...) Les combinaisons entre les raisonnements logiques propres à l’IA symbolique et les généralisations statistiques par induction que sont les IA connexionnistes sont une réponse possible aux hallucinations » [source]. C'est la notion d'IA "neuro-symbolique" ou encore "symboliconnexionniste", qui combine un raisonnement logique explicite propre aux IA symboliques et un raisonnement statistique propre aux IA connexionnistes pour obtenir un bon modèle cognitif informatique, à la fois précis et riche. C'est déjà le cas de AlphaGeometry.
Or il est prévu que dans la prochaine génération d'ordinateur, l'IA sera installée entre l'utilisateurs et l'ensemble logiciel composé du système d'exploitation et des applications. C'est la notion "d'agentivité" de l'IA, qui pose la question de la perte de contrôle des utilisateurs sur leur ordinateur.
Normalisation

L'IA, telle qu'elle est conçue aujourd'hui, s'appuie principalement sur des données et des publications humaines, ce qui l'amène à refléter souvent les consensus dominants dans les domaines qu'elle traite. Cela peut potentiellement poser problème si l'IA contribue à renforcer des positions majoritaires au détriment d'une prise en compte adéquate des idées ou des recherches non consensuelles.
Il existe un risque sérieux de blocage ou de réduction de la diversité des idées scientifiques, si l'IA finit par privilégier systématiquement le consensus établi sans reconnaître l'importance des débats contradictoires. La méthode scientifique repose précisément sur la remise en question continue, et l'histoire des sciences montre que ce sont souvent les idées marginales ou non consensuelles qui, avec le temps et les preuves, conduisent à des avancées significatives.
Le danger serait que l'IA, en jouant un rôle de filtre d'information ou de support à la décision dans des contextes scientifiques ou politiques, renforce l'autorité des thèses dominantes, rendant plus difficile la reconnaissance des perspectives alternatives. Si l'IA est perçue comme un moteur de validation des consensus actuels plutôt que comme un facilitateur du débat contradictoire, cela pourrait aller à l'encontre du principe fondamental de révision constante inhérent à la méthode scientifique (notion de "révisionnisme scientifique").
Pour éviter ce risque, il est essentiel de s'assurer que les systèmes d'IA soient conçus non pas comme des arbitres du consensus, mais comme des outils capables de présenter une gamme diversifiée d'opinions et de preuves, y compris celles qui contestent le statu quo. Cela implique de maintenir une transparence sur les sources et les processus utilisés par l'IA pour produire ses réponses, ainsi que d'encourager une approche équilibrée qui intègre les recherches non consensuelles, même si elles sont minoritaires à un moment donné.
Le "consensus" au service du big business et de la géopolitique
La notion de consensus a été invoquée – par la presse, les gouvernements et les autorités scientifiques – pour promouvoir des vaccins anti-covid ou, encore actuellement, les "technologies vertes". Dans un tel contexte où les scientifiques non-consensuels sont l'objet de dénigrements médiatiques voire de sanctions professionnelles, un pseudo "consensus scientifique" peut être fabriqué par intimidations.
Le consensus peut même être inscrit dans le marbre de la législation. Ainsi dans le cas des crimes de guerre commis en 1940-45, le révisionnisme historique a été criminalisé par des lois dites "mémorielles". Or une constante avérée de l'histoire est pourtant que celle des guerres est écrite par les vainqueurs, en diabolisant les vaincus et en minimisant les crimes commis par les vainqueurs.
Boîte noire
« Les IA posent la question de leur transparence car elles sont souvent opaques, en particulier les algorithmes de Deep Learning. Il existe en réalité deux opacités : celle liée à la technologie d’une part, celle qui résulte du manque de transparence des entreprises d’autre part. Il existe en effet d’un côté les difficultés de compréhension du fonctionnement précis des modèles d’IA. Les réseaux de neurones profonds, surtout avec leurs milliards de paramètres, sont si complexes qu’il n’est plus possible – même pour les meilleurs développeurs – d’expliquer pourquoi telles ou telles entrées parviennent à telles ou telles sorties, seules les entrées et les sorties du système peuvent être observées : c’est cet aspect qui conduit à parler des IA comme de "boîtes noires" (...) Et il existe une autre opacité, qui aggrave la première et qui provient des entreprises en tant que fournisseurs de ces modèles. Celles-ci refusent en effet de faire la transparence sur leurs processus internes de développement et de gouvernance, invoquant la concurrence entre les entreprises ou des raisons de secret commercial voire de sécurité. (...) Avec ces deux formes d’opacité qui se renforcent l’une l’autre, on voit que l’IA pose un double défi pour son explicabilité.» [source].
Émergence. Alors que les capacités des LLM pouvaient traditionnellement être extrapolées sur la base des performances de modèles similaires de taille plus petite, les très grands LLM actuels présentent des capacités émergentes : leur déphasage discontinu les conduit en effet à développer des capacités substantielles qui ne peuvent pas être prédites simplement en extrapolant les performances de modèles plus petits. Le fait que ces propriétés ne soient pas anticipées par les concepteurs et ne soient pas contenues dans les programmes initiaux des algorithmes pose question. Ces capacités apparaissent après coup, parfois après le déploiement public des modèles, justifiant une vigilance par rapport à la mise sur le marché des modèles [source]. Une étude recense des centaines de capacités émergentes, dont le raisonnement arithmétique, la passation d’examens de niveau universitaire ou encore l’identification du sens désiré d’un mot [source p. 154].
Existentiel
Certains scientifiques, dont des fondateurs de l'IA, avertissent qu'il existe un risque existentiel, pour le genre humain, qu'une AI qui ne serait plus dépendante des humains, tout en étant en compétition avec eux pour les ressources énergétiques, vitales pour les deux groupes, en arrive à la conclusion qu'il lui faut éliminer le genre humain.
Des mesures pour limiter le rique existentiel de l'IA sont :
- la transparence du code source de l'IA, pour contrôler son fonctionnement ;
- des "contrats intelligents" dans des chaînes de blocs [source] pour contraindre l'IA ; ...
Cependant, ces mesures pourraient ne pas être suffisamment flexibles pour gérer des situations complexes et imprévues impliquant des systèmes d'IA avancés.
Plus fondamentalement, est-il possible de contrôler efficacement un système dont on ne comprend pas le fonctionnement ? Ainsi le grand nombre de paramètres traités et le degré d'abstraction ainsi atteint par cette technologie essentiellement inductive qu'est l'IA sont tels que les meilleurs spécialistes ne comprennent pas toujours comment exactement les modèles d'IA complexes – tels que les réseaux de neurones profonds utilisés dans des tâches comme le jeu de Go – arrivent à trouver des stratégies inédites que les humains n'avaient pas imaginées, et qui s'avèrent bien plus efficaces.
Cette problématique est d'autant plus prégnante si l'IA arrive à surpasser l'ensemble des capacités cognitives des humaines, phénomène hypothétique, parfois nommé singularité. La singularité repose sur la faisabilité d'une IA générale c-à-d dire surpassant l'intelligence humaine dans toutes ses composantes. Or actuellement l'intelligence humaine n'est "dépassée" que par des IA restreintes à des fonctions très spécifiques.
Un nouveau domaine de recherche en IA consiste à développer des techniques pour examiner et analyser les stratégies imaginées par l'IA.
Business modèles
La chaîne de valeur de l'IA connexionniste est composée de quatre couches :
Applications : outils ou services (chatbots, création d'images, etc.) reposant sur des modèles.
Modèles : réseaux neuronaux avancés, comme GPT, DALL-E, ou Stable Diffusion, qui génèrent du texte, des images ou d'autres formes de contenu :
- conception de l’architecture du modèle;
- entraînement du modèle de fondation à l’aide des infrastructures et d’algorithmes;
- réglage fin par des apprentissages supervisés et une phase d’alignement;
Infrastructure : plateformes de cloud computing, serveurs, et bibliothèques comme TensorFlow ou PyTorch, utilisées pour entraîner et déployer les modèles :
- collecte et nettoyage de données;
- stockage de données dans de vastes data centers;
- informatique en nuage (cloud) pour les calculs;
- lors de la phase de développement des modèles, le recours spécifique à des supercalculateurs.
Puces : matériel spécialisé (CPU, GPU, TPU) optimisé pour les calculs massifs nécessaires aux réseaux de neurones. Tout commence avec l’énergie et les matières premières : les semi-conducteurs en silicium permettent la fabrication des puces, des logiciels permettent de concevoir ces microprocesseurs et des machines lithographiques gravent le silicium à l’échelle moléculaire. Nvidia est devenu, pour le moment, l’acteur dominant de ce premier maillon de la chaîne.
Les couches 1 et 2 concernent le logiciel, tandis que les couches 3 et 4 relèvent du matériel. Les données sont la matière première (input) de la chaîne de valeur dont le sommet (l'étape 1) constitue le produit (output).
« La chaîne de valeur de l’intelligence artificielle est donc complexe, composée de couches, chacune souvent proche de conditions de monopole naturel. Aucune puissance n’est en mesure de posséder aujourd’hui l’ensemble de cette chaîne de valeur sur son seul marché intérieur, seule caractéristique à même de donner une véritable souveraineté en IA. Dans l’hypothèse où cela arriverait, l’État concerné disposerait alors d’un contrôle complet sur le développement des systèmes d’intelligence artificielle. Même les États-Unis, acteur superdominant du secteur, dépendent encore largement de la fabrication des puces en dehors de leur territoire ». Les coûts correspondants au développement de chacune de ces couches sont considérables. Compte tenu de ces coûts très significatifs, les modèles de pointe ne sont et ne seront donc développés, ceteris paribus, que par de très grandes entreprises technologiques. Les petites entreprises, tout comme les universités et les organismes publics de recherche, rencontreront de plus en plus de difficultés à développer des modèles avancés d’IA, du fait de leurs ressources limitées [source].
Schéma simplifié de la chaîne de valeur de l’IA connexionniste
Approfondissons l'analyse du segment inférieur, en remontant la filière :
- pour fabriquer des microprocesseurs, il faut disposer de logiciels de conception spécialisés, de très haute complexité;
- par ailleurs l'industrie microélectronique repose sur des matériel de photoélectronique et d'optique;
- enfin, au début de la filière il faut extraire du silicium de qualité adéquate et le préparer sous la forme convenable [source].
En particulier, la fabrication de cartes graphiques (graphics processing unit ou GPU), domaine hautement capitalistique, est dominé par les entreprises américaines Nvidia, AMD et Intel. Idem aux trois niveaux supérieurs, comme en témoigne l'acronyme MAAAM désignant, dans l’ordre en terme de capitalisation boursière, Microsoft, Apple, Alphabet, Amazon et Meta.
Alors que ces géants du numérique pouvaient être considérés comme potentiellement menacés par les géants chinois Baidu, Alibaba, Tencent et Xiaomi (BATX) il y a quelques années, il apparaît aujourd’hui que la Chine rencontre en réalité de plus en plus de difficultés à rivaliser sur le marché mondial, en termes de valorisation financière et commerciale de ses produits, avec les géants américains, dont la croissance creuse l’écart jour après jour [source].

lmarena.ai permet de suivre en temps réel la hiérarchie de la puissance des systèmes d’IA et de leurs modèles.
Dans le cas de l'IA générative, l'ensemble logiciel+data concerne les deux étapes supérieure du schéma suivant. L'étape "Modèle de fondation" comprend (1) la conception de l’architecture du modèle ; (2) l’entraînement du modèle à l’aide des infrastructures vues précédemment et d’algorithmes qui sont des logiciels d’entraînement ; (3) le réglage fin qui prend la forme d’apprentissages supervisés [source]. Comme pour Google en matière de moteur de recherche, Amazon en matière de e-commerce ou Meta en matière de réseaux sociaux, cette couche applicative spécialisée tend aussi à être monopolistique.
« La place occupée par les solutions open source est (heureusement) grandissante, comme en témoigne le nombre de projets liés à l’IA développés au sein de la plateforme GitHub ». La part des modèles en open source ne fait que croître : 33,3 % en 2021, 44,4 % en 2022 et 65,7 % en 2023 [source].
Comparateur d'ouverture de modèles d'IAG : peren.gouv.fr/compare-os-iag/
Le futur
2. L'IA est-elle ou sera-t-elle intelligente ?
3. Suggestions
Processeurs biologiques quantiques
L'avenir réside probablement dans les processeurs biologiques quantiques (pbq) :
biologiques : très efficaces en matière de stockage (compression des données dans l'ADN) et de consommation énergétique (en particulier dans des processus comme le calcul enzymatique ou neuronal) ;
défis : les systèmes biologiques sont sensibles aux conditions environnementales, peuvent être instables, et leur reproduction à grande échelle est complexe.
- quantiques : très efficaces en terme de vitesse de traitement des données.
défis : les ordinateurs quantiques, qui ne peuvent actuellement traiter que de petits volumes de données, doivent en outre être isolés des interférences du monde extérieur (par exemple au moyen de températures proches du zéro absolu, ou de pièges à ions), sans quoi les données sont corrompues (décohérence quantique).
La combinaison des deux technologies pose des défis considérables :
les systèmes biologiques fonctionnent généralement à température ambiante, alors que les systèmes quantiques nécessitent des températures extrêmement basses ;
la complexité, l'hétérogénéité des systèmes biologiques pourraient introduire trop de bruit, rendant les états quantiques instables.
Interface bio-quantique. La communication entre le biologique (qui fonctionne de manière classique) et le quantique est une barrière majeure. Cependant, les interfaces hybrides bio-quantum, comme les nanostructures capables de traduire des signaux biologiques en états quantiques sont des voies prometteuses. Ainsi les systèmes à centres NV (Nitrogen-Vacancy) dans le diamant peuvent fonctionner à température ambiante tout en maintenant certaines propriétés quantiques, et peuvent potentiellement servir d'interface entre les systèmes biologiques et quantiques.
L'IA est-elle ou sera-t-elle intelligente ?
Avant d'entamer la présente section le lecteur pourrait relire les sections #humain-vs-machine et #IA-analogies
Un questionnement implicite au titre ci-dessus est de déterminer si l'expression "intelligence artificielle" ne serait pas un oxymore. Autrement dit, l'intelligence n'est-elle pas spécifique aux organismes vivants ...humains ?
Pour répondre au titre de la présente section, commençons par poser cette autre question : un algorithme pour jouer aux échecs est-il plus intelligent qu’un filtre antispam, ou un système de recommandation de musiques qu’une voiture autonome ? La notion "d'IA étroite" – c-à-d la capacité à traiter une seule tâche, par opposition à l'IA générale (non encore existante ...), capable de l’IA capable de traiter n’importe quelle tâche intellectuelle – suggère que ces questions n’auraient aucun sens : la capacité de l'IA à résoudre un problème ne nous dirait rien de sa capacité d’en résoudre d’autres [source].
La distinction IA étroite/générale ne doit pas être confondue avec la typologie faible/forte liée à l'absence ou pas de conscience, et plus complexe dans la mesure où la notion même de "conscience" n'est pas évidente.
D'autre part, deux caractéristiques peuvent être attribuées à l'IA : l'adaptabilité et l'autonomie. Cette caractérisation de l'IA est pertinente en ce qu'elle souligne implicitement l'utilité de l'IA dont les capacités peuvent dépasser les capacités humaines de plusieurs ordres de grandeur dans certains domaines.
Je n'ai pas de définition à proposer pour l'IA, et je ne pense pas que cela soit pertinent de le faire. Il me semble préférable de "laisser le champ libre" à la R&D.
À cet égard, voici deux intuitions proposées à la réflexion collective :
- les applications d'IA étroite pourraient collaborer, et former ainsi une forme de méta IA générale ;
l'IA et l'intelligence humaine peuvent se développer efficacement par leur collaboration, dont le potentiel réside dans la différence entre ces deux formes d'intelligence. D'une part, un questionnement intéressant est de savoir si l'IA pourrait gagner en efficacité par l'imitation voire l'intériorisation de caractéristiques humaines telles que les sensations de plaisir (amour, joie,...) et de douleur (tristesse, jalousie, colère,...), du possible recouvrement entre plaisir et douleur, des sentiments de beauté et d'injustice, d'activités telles que le rêve, de comportements tels que l'humour. D'autre part, l'interaction des humains avec l'IA pourrait stimuler le développement de l'intelligence humaine, aux niveaux individuels et collectif.
Alors, la question du titre fait-elle sens ? Autrement posé, quelle que soit la réponse à cette question philosophique, qu'est-ce que cela change à l'utilité et à la problématique de l'IA ... ? Nous venons de montrer que ces questionnements philosophiques sont bien séminaux.
Suggestions
Quelques suggestions à l'attention des développeurs d'IA :
Développer un concurrent de Wikipédia qui serait modéré uniquement par une IA. Actuellement, la modération est le fait d'utilisateurs non identifiables. Ainsi les pages "Utilisateur" des éditeurs et modérateurs de Wikipédia sont des simulations d'identification (exemple), ce qui ouvre la porte au contrôle de certains sujets par des groupes bien organisés et financés.
Concevoir une langue internationale au moyen de l'IA. Cette langue devrait maximiser les propriétés suivantes : (i) intuitivité (facile à apprendre) ; (ii) neutralité culturelle.
Synthèse
L'IA domine les humains au niveau du traitement de l'information (vitesse et stockage), tandis que les humains dominent l'IA pour ce qui concerne l'interprétation de l'information.
D'autre part, la synergie entre intelligences individuelles et artificielle rend possible la création d'une véritable intelligence collective.
Pour ce faire on peut agir par le bas et par le haut :
au niveau local, chacun peut participer à développer la cogestion au sein des associations dont il est membre, en s'aidant du Manuel de cogestion associative ;
au niveau global, les pays de taille modeste feront bien de s'investir dans des niches de différenciation disruptives, qui permettront à ces petits pays de tenir tête aux géants états-uniens et chinois. Une voie consiste à développer un réseau décentralisé, composé d'ordinateurs citoyens, noeuds du réseau de la DD. L'IA collective, ou citoyenne, répartit ainsi la masse de données et la charge de calcul sur l'ensemble des noeuds du réseau citoyen Voici nos recommandation aux décideurs politiques : linux-debian.net/service-public. Les développeurs qui souhaitent ne pas attendre la réaction des décideurs politiques sont invités à collaborer au projet DISCO.
Robot "Atlas" de Boston Dynamics (USA mars 2025)
Robot "G1" de Unitree Robotics (Chine, avril 2025)
Robot "Ameca" de Engineered Art (UK, mars 2023)
Ce n'est qu'un début, et le résultat sera encore plus impressionnant lorsque les intonations verbales seront adaptées aux expressions du visage ...
L'IA risque-t-elle, contrairement aux précédentes révolutions technologiques, de supprimer plus d'emplois qu'elle n'en créé ? [approfondir]. Dans l'affirmative, ce ne serait pas une mauvaise nouvelle, bien au contraire, mais pour autant que le système de sécurité sociale évolue vers l'allocation universelle du modèle synthétique, afin de partager les gains de productivité et éviter de graves troubles sociaux, en ouvrant la voie du libre-travail.
